加密的C实现
先学会怎么使用
MD5
使用
这里借用了一个MD5实现的cpp文件。
这个结构包括三个count:数据长度、state:算法初始化常量、buffer:明文数据
具体的先不管,用了再说

1 | // 这里实现的MD5主要依靠一个结构体和三个方法 |
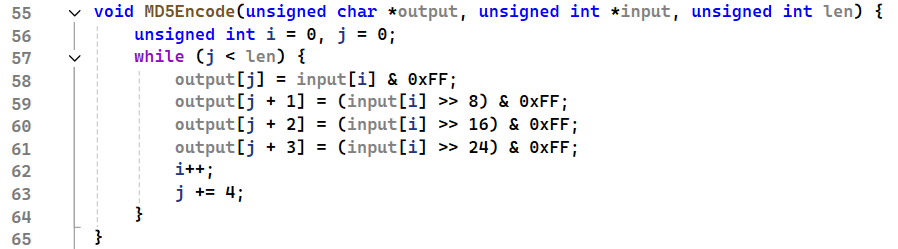
这样的得到的结果是 unsigned char 的形式,是不能直接查看的,需要进行一种编码,hex或者base64。
hex比较简单
1 | // 对加密结果进行hex编码 |
这样就实现了一个MD5的简单使用
处理明文
MD5处理明文的过程
1、对明文进行hex编码
2、填充
将明文填充到448bit
先填充有关1,后面跟对应位数的0。 1000 0000
448/8 = 56,很显然不够正,因为还留了64bit,作为附加消息长度
附加长度之后是这样的:00 00 00 00 00 00 00 50 。
最后50计算是bit位,明文数据10字节,10*8bit = 80bit,转换成hex就是50
但是MD5是小端字节序应该变为: 50 00 00 00 00 00 00 00
明文最后处理成
61 31 32 33 34 35 36 37 38 39 ==80== …… 50 00 00 00 00 00 00 00
如果内容过长64bit放不下,就取低64bit。所有MD5输入长度可以无限大,SHA3算法同理
3、MD5输入数据无限大,不可能一起处理,需要分组
4、MD5的分组长度为512bit,数据需要处理到512的倍数,因此需要填充
5、填充位数为 1-512bit,如果明文长度刚好448bit,那么就填充512bit
字节序
所谓的字节序就是hex形式的字节在内存中的存放方式
一个int类型占四个字节,定义一个100,按道理来说00 00 00 64,如果是这种存储方式那么就是大端字节序
通过定义 char,将字节挨个取出,发现在内存中是这样的 64 00 00 00,这就是小端字节序的存储,转换就是 1-4 2-3 3-2 4-1
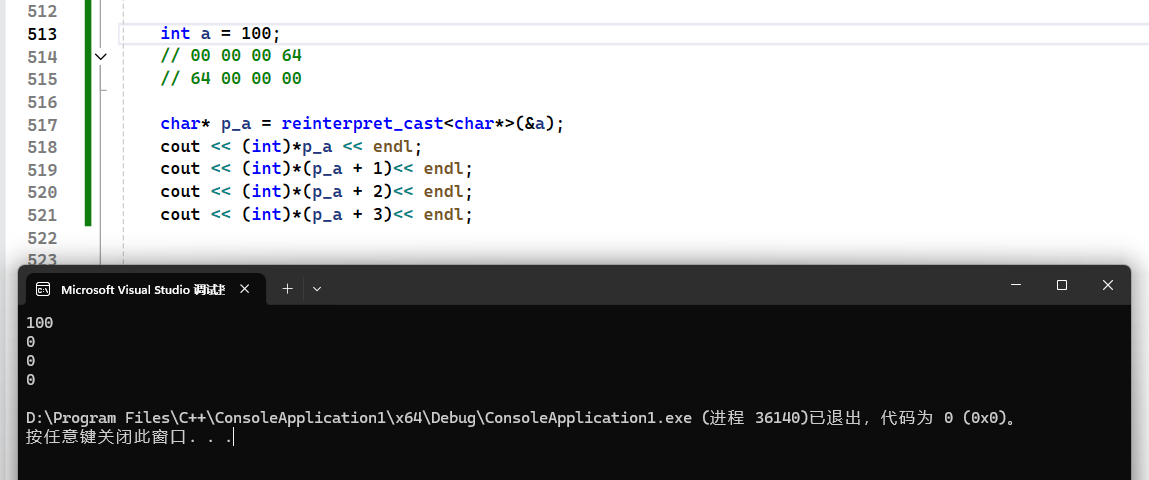
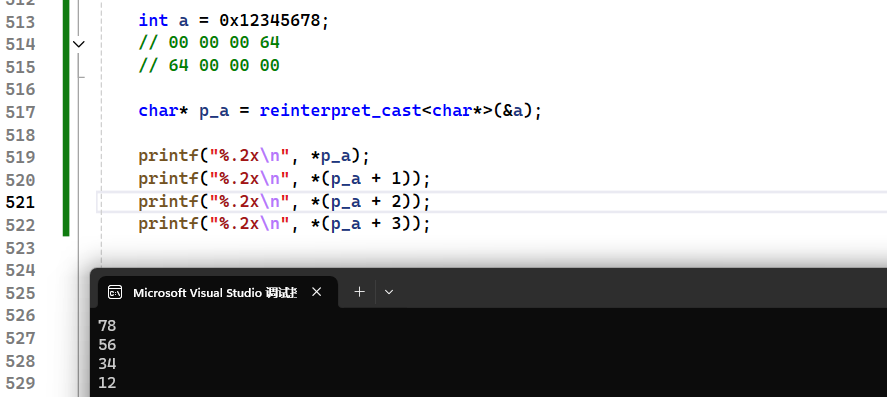
也就是说如果内存中int数据为 78563412 的时候表示出来是0x12345678
算法细节
处理成512bit的明文数据之后,明文会分成16部分M1-M16,用于后续处理
1 | 61 31 32 33 34 35 36 37 38 39 80 00 …… 50 00 00 00 00 00 00 00 |
512/16 = 32bit,每组四字节
| 实际需要的值 | 内存中小端字节序 | |
|---|---|---|
| M1 | 61 31 32 33 | 33 32 31 61 |
| M2 | 34 35 36 37 | 37 36 35 34 |
| M3 | 38 39 80 00 | 00 80 39 38 |
| …… | …… | …… |
| M15 | 50 00 00 00 | 00 00 00 50 |
| M16 | 00 00 00 00 | 00 00 00 00 |
MD5的初始化常量
这个词在一开始创建结构体的时候提到过 state[4] 代表的是初始化常量,那么在MD5Init中干了什么呢
给初始化常量赋值
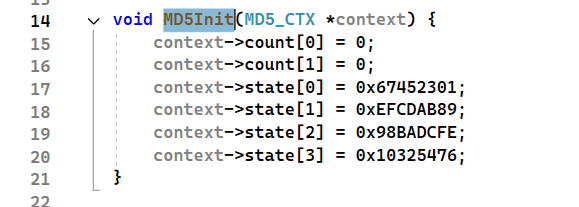
因为要求在内存中数据如下
A:01 23 45 67
B:89 ab cd ef
C:fe dc ba 98
D:76 54 32 10
所以在代码中按照以上方式进行赋值。给这玩意改了照样能算,能运行,但就是不是标准的MD5了
循环计算
这里的ABCD代表初始化常量,Mi就是上面的分组16组
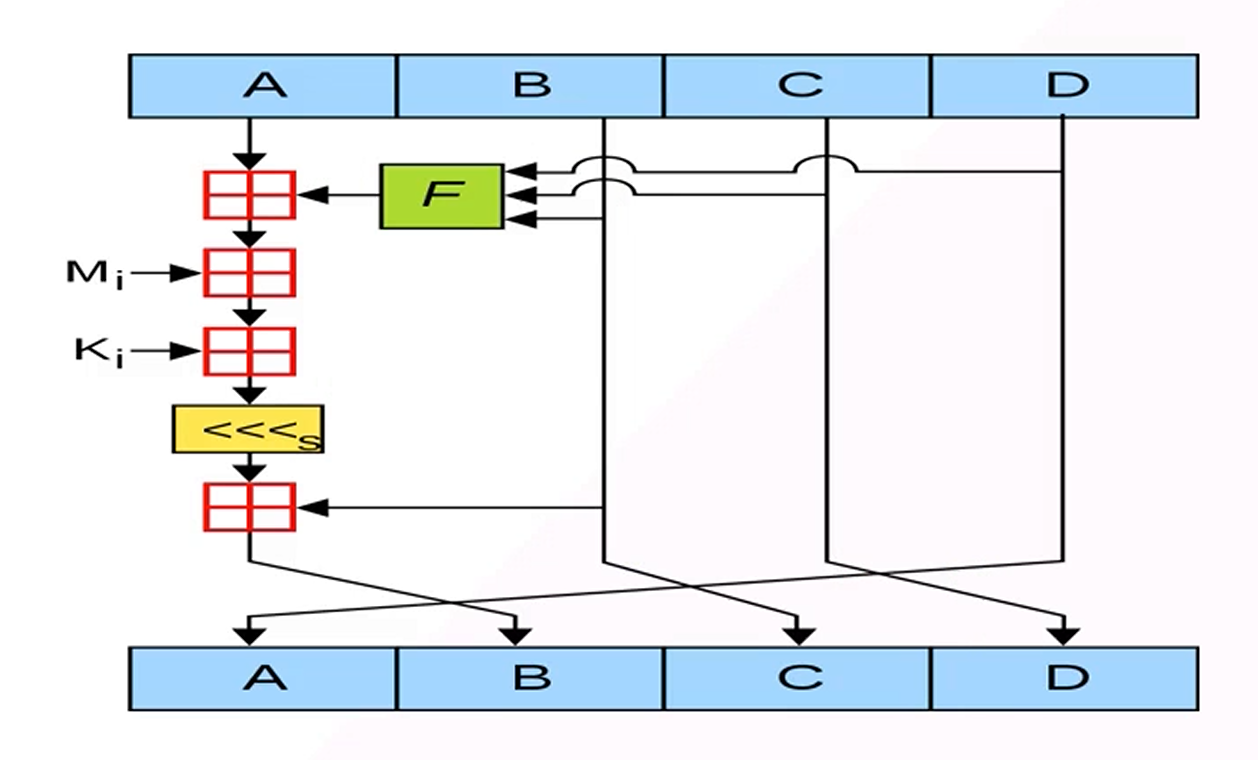
MD5总共64轮,每一轮会将旧的D直接给A,B-C,C-D,然后用旧的A来计算出新的B。
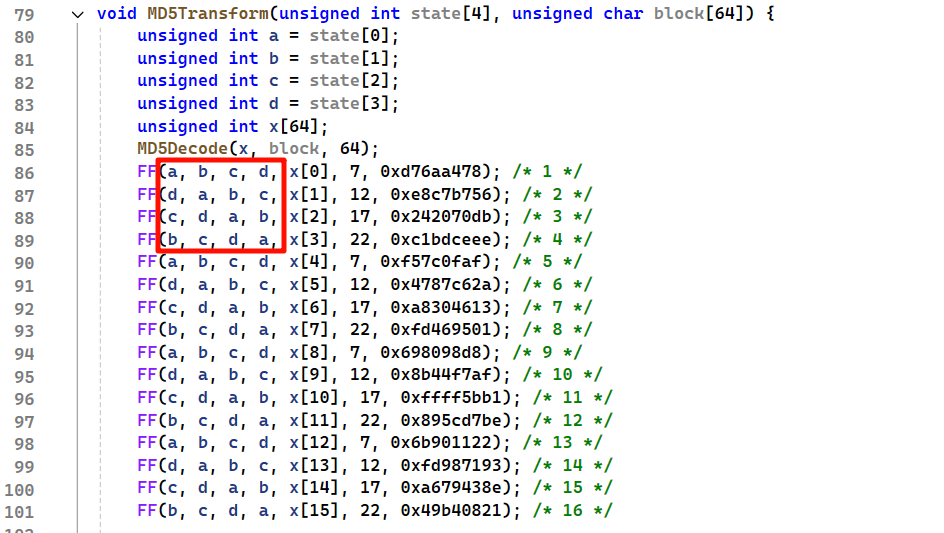
来看具体的操作,上图的 田 字就是表示加,Ki是数据常量是定值,看括号内最后一个参数就是K。K表中的值是由公式计算的,但是体现在代码中一般是常量,提高效率
s是循环左移的位数,这个也是常数,但是一般不会魔改这里,因为SHA0和SHA1的区别就是左移一位,SHA0则有安全性问题,左移我把握不住啊
F是函数,一共有四个函数,每个函数用16次 FF GG HH II
1 | A + F(B, C, D) + Mi + Ki |
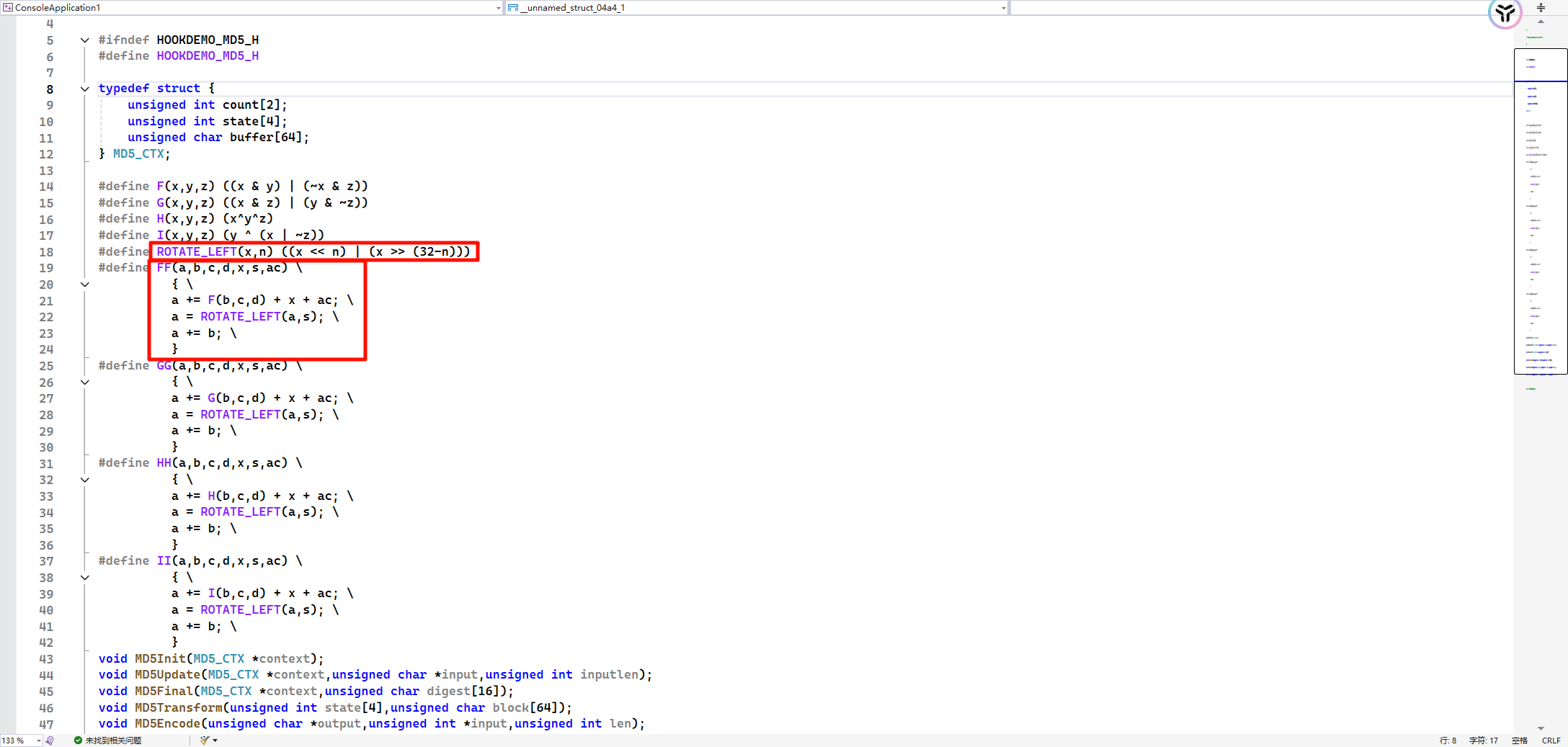
也是一通操作,然后将64轮之后的ABCD拼接在一起,成为MD5值
代码实现
之前已经从理论上了解了算法的细节问题,尝试理解吸收,看看代码实现
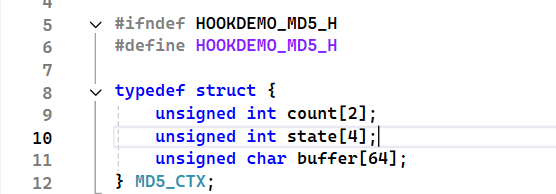
先看这个结构体,count[2] 一共八个字节来表示数据长度,最多表示4G的数据
state[4] 初始化变量
buffer[64] 64*8 = 512 正好512bit,正好处理一轮数据的
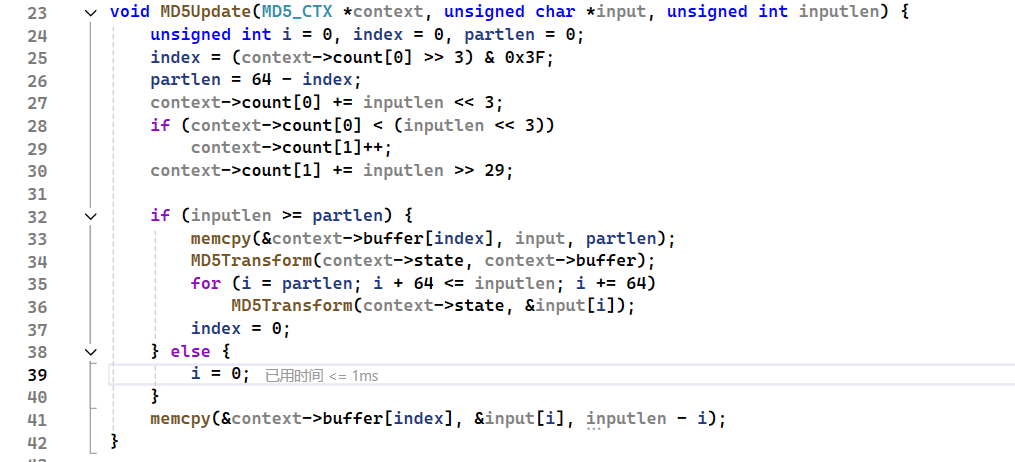
MD5Update方法是将传进来的数值进行计算,如果传入的数据不满64,也就是512bit,就暂存在Buffer中,如果数据长度到达了64,那么就开始计算这一组。因为可以多次Update,数据不够暂存是合理的
count两个值,一个计算的是明文长度,一个计算的是未使用的长度
进入Final,先计算了长度,以及需要填充的长度,MD5Encode是完成了大端序到小端序的转换
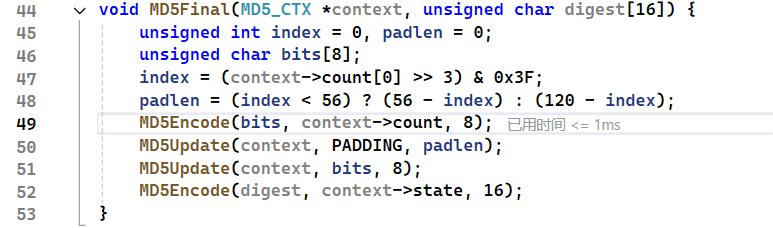
传进来int弄出去char*,就将int的四个字节拆开了,传进来的是count,只有两个int,bits是八个,就是用来计算末端的小端字节序的。
count的两个值为 72 0
虽然内存中分别为 72 00 00 00 、00 00 00 00。但是使用int来获取出来的还是大端字节序,使用异或和右移的方法,取出小端字节序来。和之前查看内存的小端字节序
以12 34 56 78为例。这是大端字节序,先异或将 78 作为output[0],然后右移8位 00 12 34 56,再取出 56,再右移8位 00 00 12 34 ,取出 34 ,右移八位 00 00 00 12,取出12,最后的输出结果就是 78 56 34 12。
计算完之后,先压入padding,前面已经计算好了需要传入的个数,再压入字节序。压入bits的时候,就符合分组长度了,进入MD5Transform。
MD5Decode就是将64位的数据分成16组,M1-M16,主要通过左移来实现
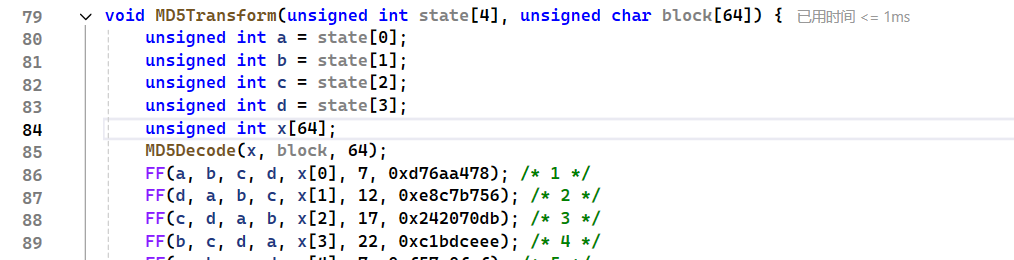
结尾处理实际+=,下一轮循环会继续拿着这个结果继续计算
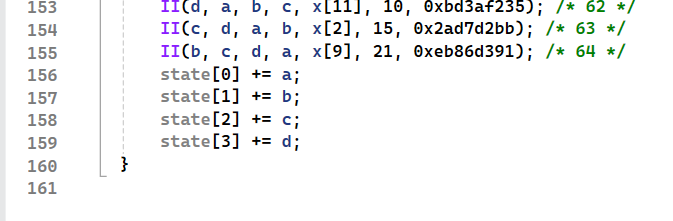
MD5Transform已经没啥好说的了,就是64次循环计算,利用四个函数来进行加的操作,然后每次循环产生新的B,最后得到一个新的 初始化常量 ,这个就是加密后的结果
计算完之后,得到初始化常量的数组,再次调用MD5Encode转换回来,得到MD5的计算结果
IDA插件
python环境
少年你是否还是一打开IDA先报个错呢。八成是python环境没弄好,启动 idapyswitch.exe 选中一个python环境即可,闪退不要紧,原地打开命令行,输入
1 | idapyswitch.exe |
如果没有搜寻到电脑中的python版本也不要紧,我就没搜到,使用命令告诉他在哪
1 | idapyswitch --force-path yourPath |
成功之后,妈妈再也不用担心我打开IDA被叮咚吓一跳了
认识IDA
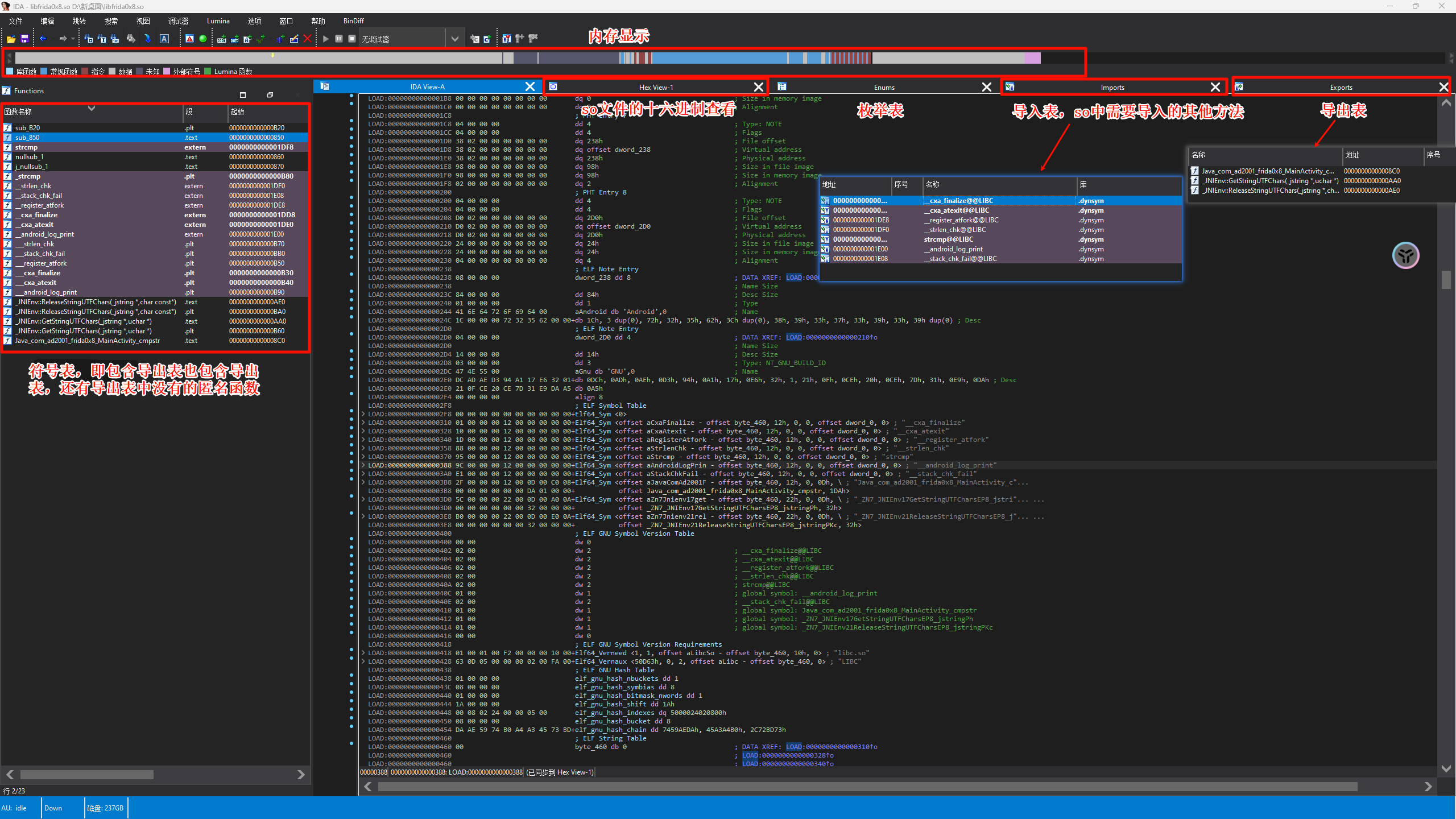
快捷键
CTRL+S 查看段信息,在IDA-View中,开头也是包含段信息的
| 段信息 | 含义 |
|---|---|
| .text | 表示代码段 |
| .data | 表示数据段,包含全局变量和静态变量 |
| .bss | 未初始化数据段 |
| .rodata | 只读数据段,如字符串常量 |
| .rdata | 资源数据段 |
| .symtab | 符号表,包含函数名和变量名 |
| .strtab | 字符串表 |
| .rela | 重定位段 |
| .hash | 哈希表 |
| .dynsym | 动态符号表 |
| .dynstr | 动态字符串表 |
| .dynamic | 动态链接信息 |
| .plt | 过程链接表 |
| .got | 全局偏移表 |
快捷键,无需多言
| 快捷键 | 作用 |
|---|---|
| F5 | 反编译为伪C代码 |
| ctrl+s | 查看段 |
| Tab | 切换代码窗口和反编译窗口 |
| 空格 | 切换代码窗口和图形窗口 |
| C | 将数据转为代码 |
| G | 地址跳转 |
| X | 交叉引用 |
| Shift+; | 添加注释 |
| ESC | 返回上一步 |
| Shift+F12 | 打开字符串窗口 |
| F1 | 帮助 |
| F2 | 添加断点 |
| A | 转换为ASCII码 |
| D | 转换定义数据 |
| H | 转换10进制和16进制 |
| M | 更改符号常量 |
| N | 更改变量的名称 |
| P | 将代码定义为函数 |
| Y | 更改变量的类型/函数类型 |
| Shift+F3 | 打开函数列表 |
| Shift+F5 | 打开签名列表 |
| Shift+F9 | 打开结构体窗口 |
插件
自带的F5插件不多说,和算法有关的还有几个插件 Findcrypt Signsrch
Findcrypt 主要是对于AES、DES算法的识别对哈希算法识别效果并不理想,但是也是可以识别出来一部分的
看一下他的匹配规则,有些时候有混淆什么的,太绝对了,匹配效果不是很好
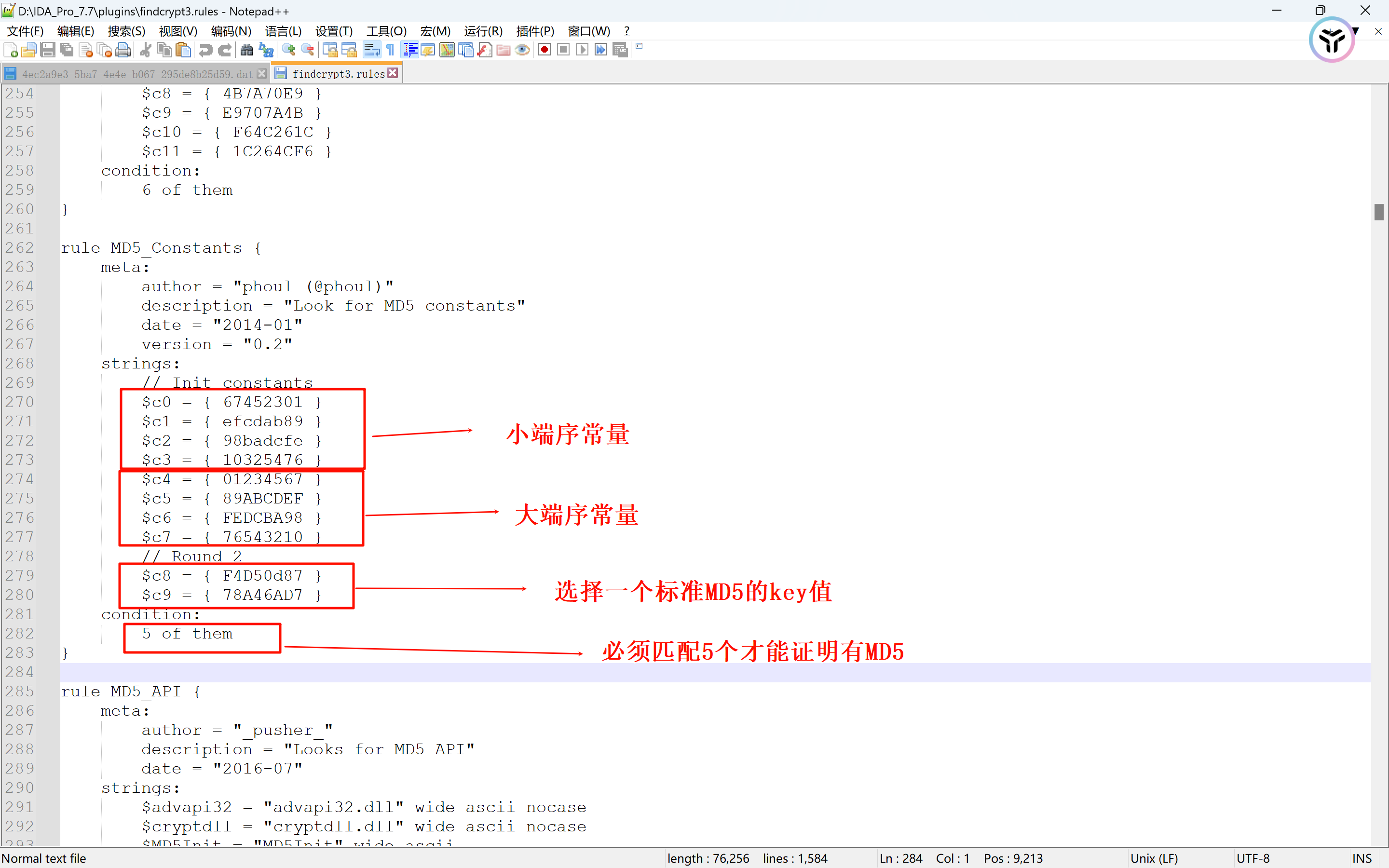
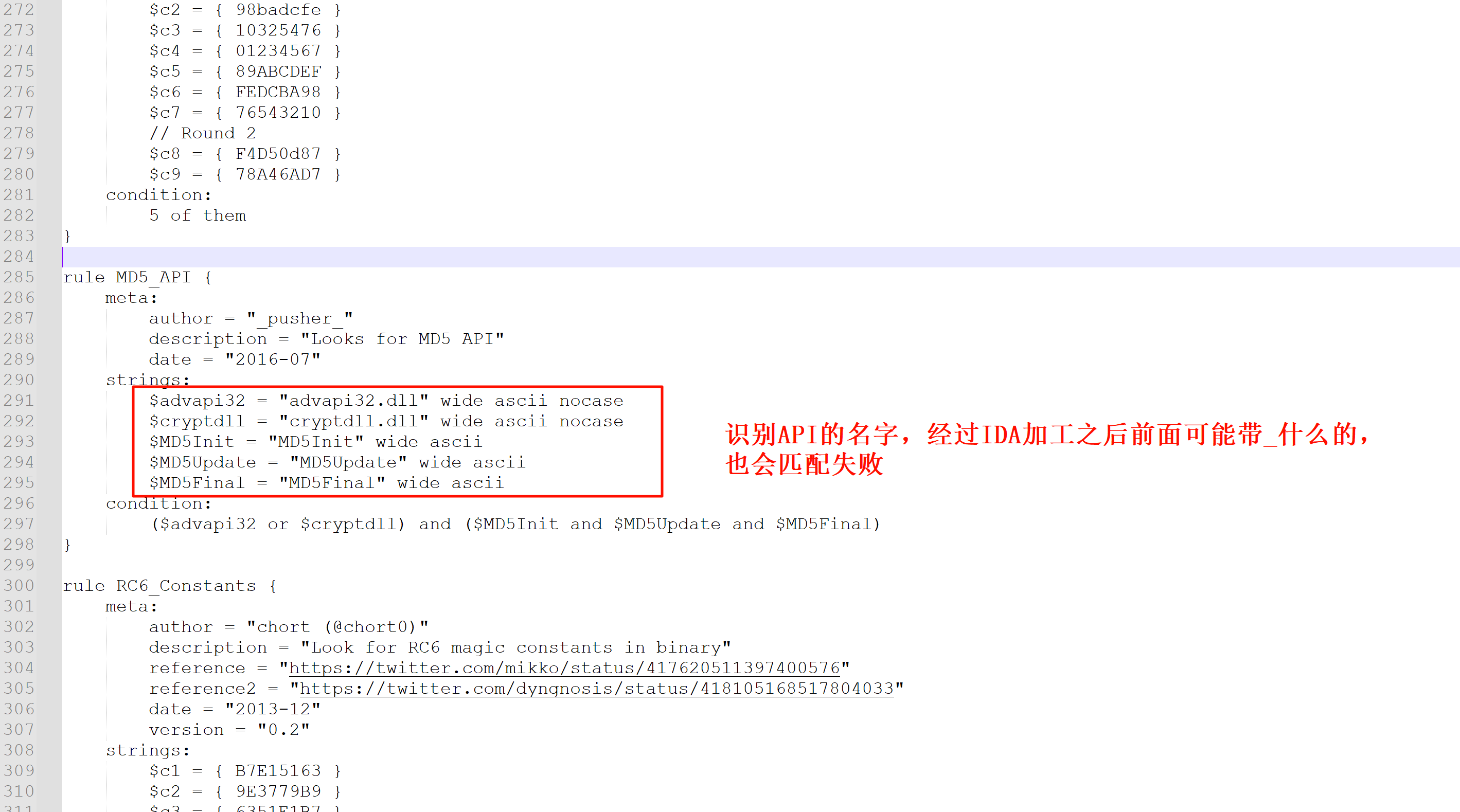
利用findhash插件自吐
findhash插件可以检测哈希函数,并且生成一个frida代码,并且这个代码是可以进行hook打印地址信息的
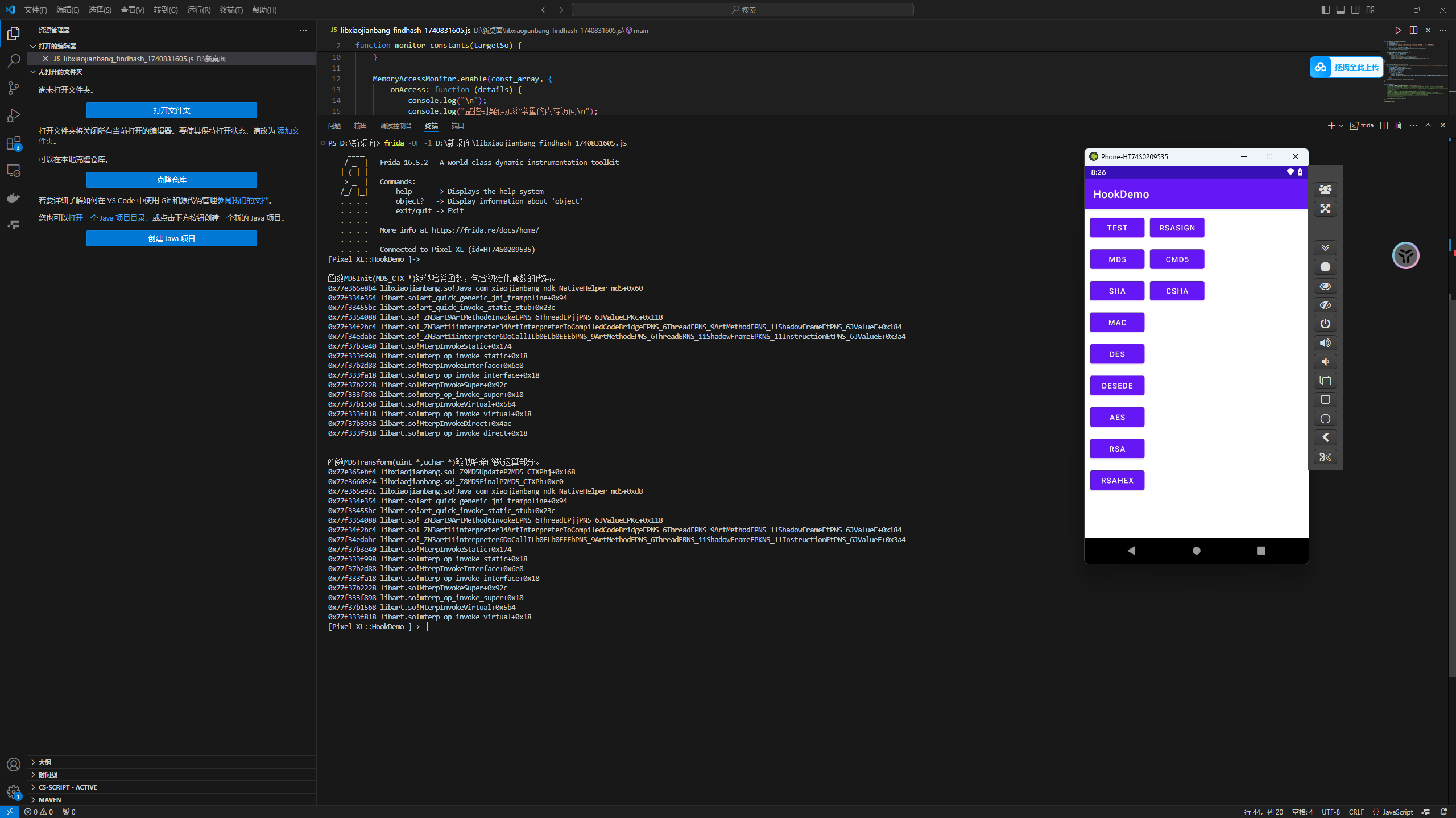
这样利用这个代码距离自吐算法还差打印一些参数,但是呢这个插件识别的方法有限。
在生成的js脚本中添加两个方法来打印传入值和返回值(C一般没返回值,打印运行结束后的传入值)
1 | function print_arg(addr) { |
traceNatives插件
这个插件是生成一个txt文件,文件内是frida指令,hook了他所检测到的一些函数偏移地址

直接运行看看
1 | frida-trace -UF -O .\libxiaojianbang_1740836169.txt |
这个是将函数调用的流程给打印了下来
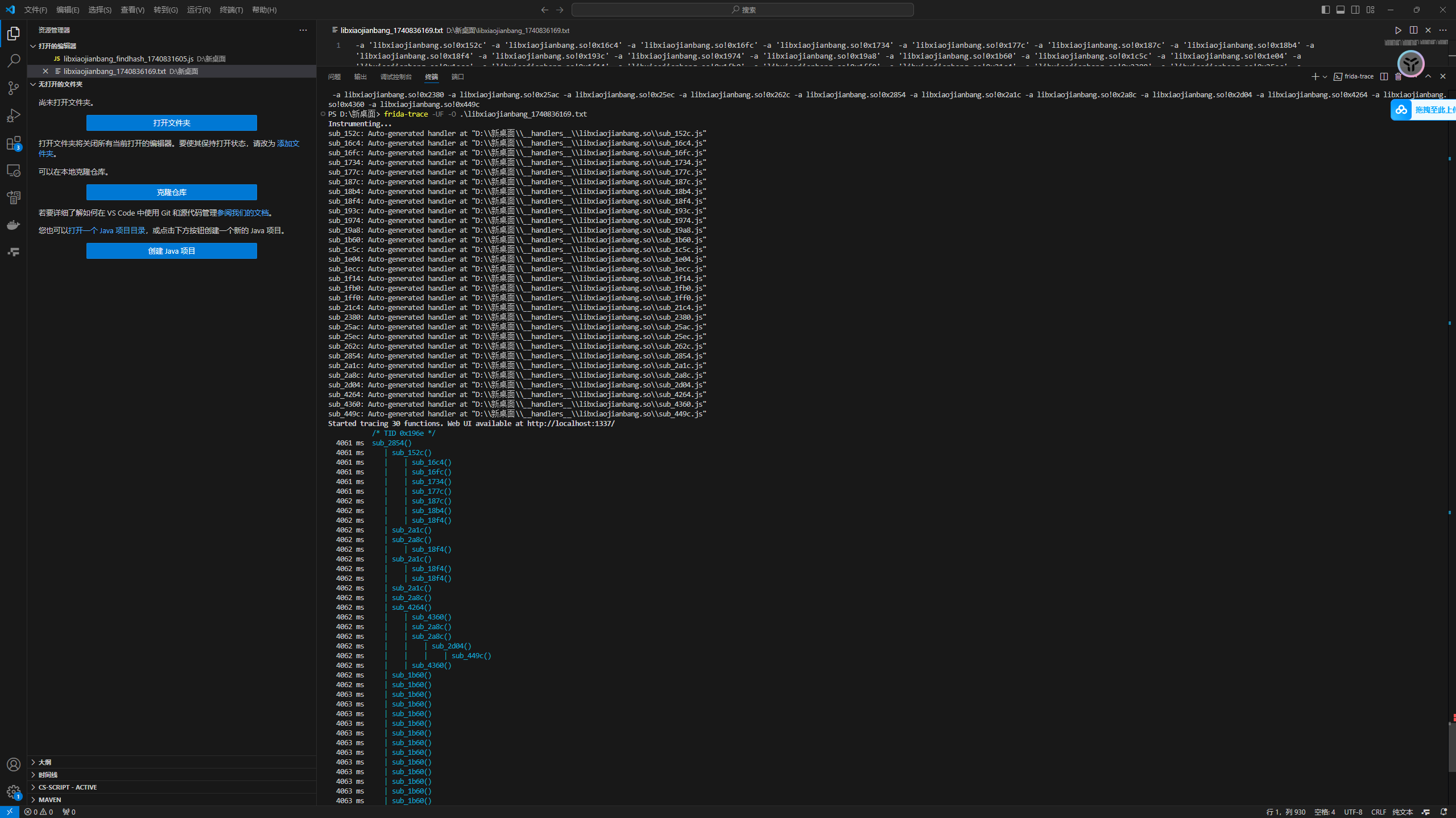
研究一下py文件
这个东西是将代码超过十行的方法记录下来,然后利用frida-trace将这些函数hook掉,打印函数调用流程
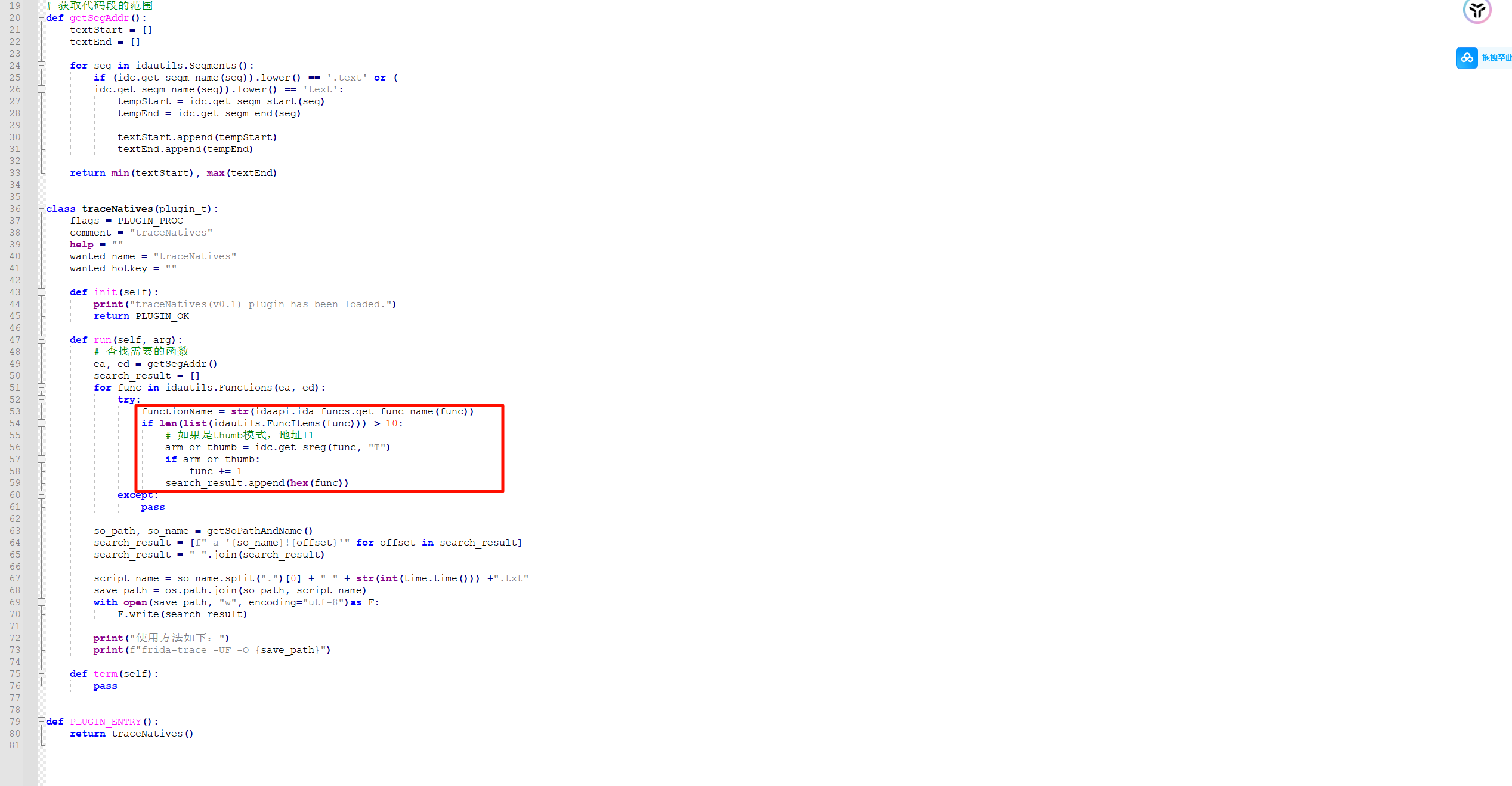
小改一下
1 | def generate_script(funclist, so_name): |
再生成一个js文件,将超过十行的函数hook一下
SHA1
初步认识
1、SHA1算法对于明文的处理和MD5相同,区别是最后的消息长度是==大端字节序==(SHA家族的都是大端字节序)。SHA1和MD5都是从MD4算法改进出来的算法,基本思路都是将信息分为N个分组,每组64字节(512bit),每个分组都进行摘要运算。当一个分组运算完毕之后,将上一个分组的结果用于下一个分组的运算(感觉很像CBC模式,但是CBC模式是保留中间过程的运算结果的,信息摘要只保留最后一次的运算结果)。明文信息长度(bit长度,而非字节长度)用64bit表示,是作为补充信息在最后一个分组的末尾
1 | 示例: |
2、SHA1的分组长度是512bit,明文也要分段,类似Mi,区别是有80段(MD5有16个段M1-M16),SHA1的前16段也是对512字节进行分段,但是还扩展了64段,一共80段。遵循大端字节序,在代码中不需要像MD5一样看着很别扭
3、SHA1和SHA0的区别就是在扩展这64段的时候,增加了循环左移一位,仅一行的差别
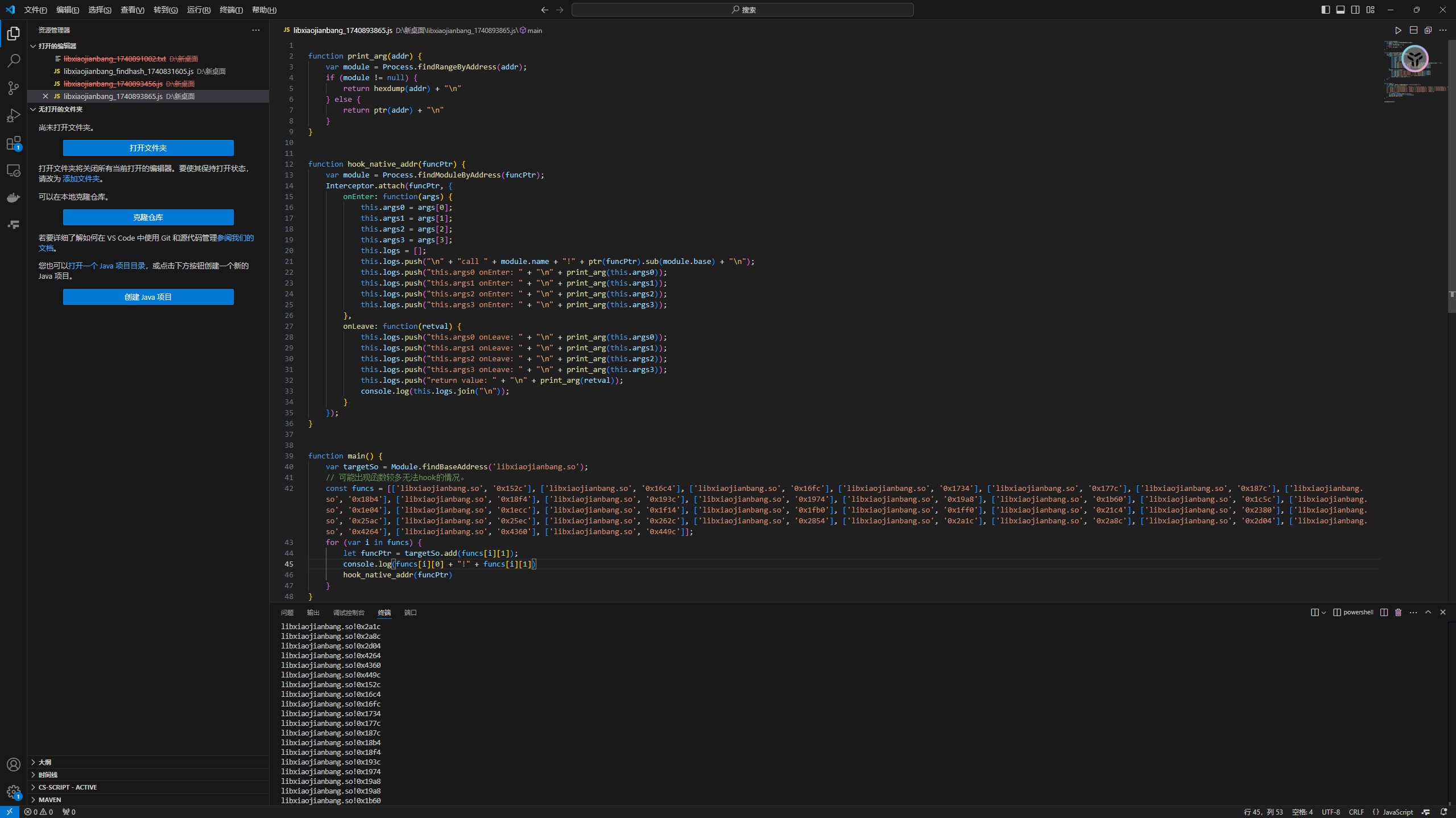
1 | W[t] = SHA1CircularShift(1, W[t-3]^W[t-8]^W[t-14]^W[t-16]); ——SHA1 |
但是就是差这一位的左移,导致SHA0有安全隐患,因此在魔改算法的时候,一般不会对左右移下手
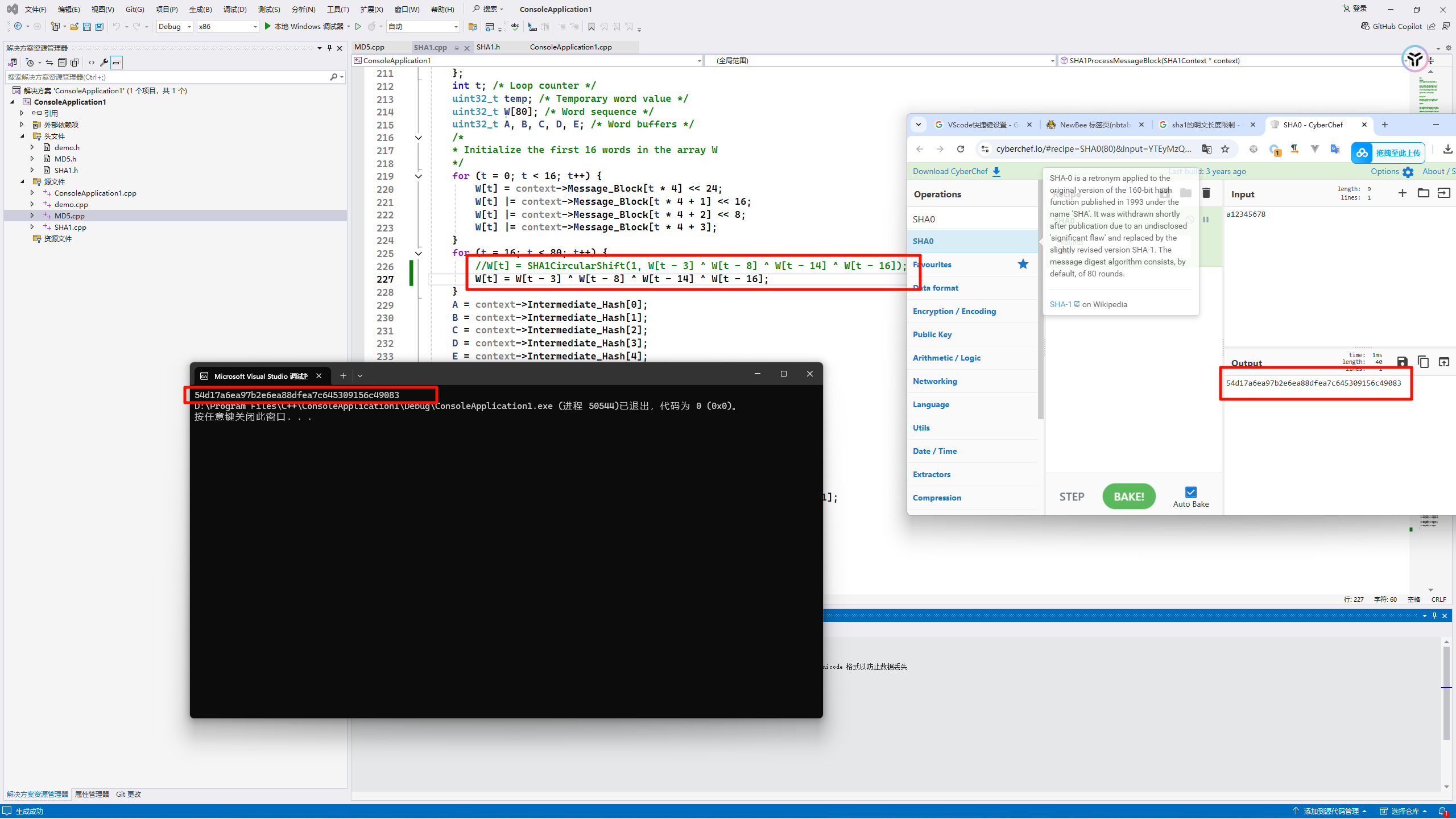
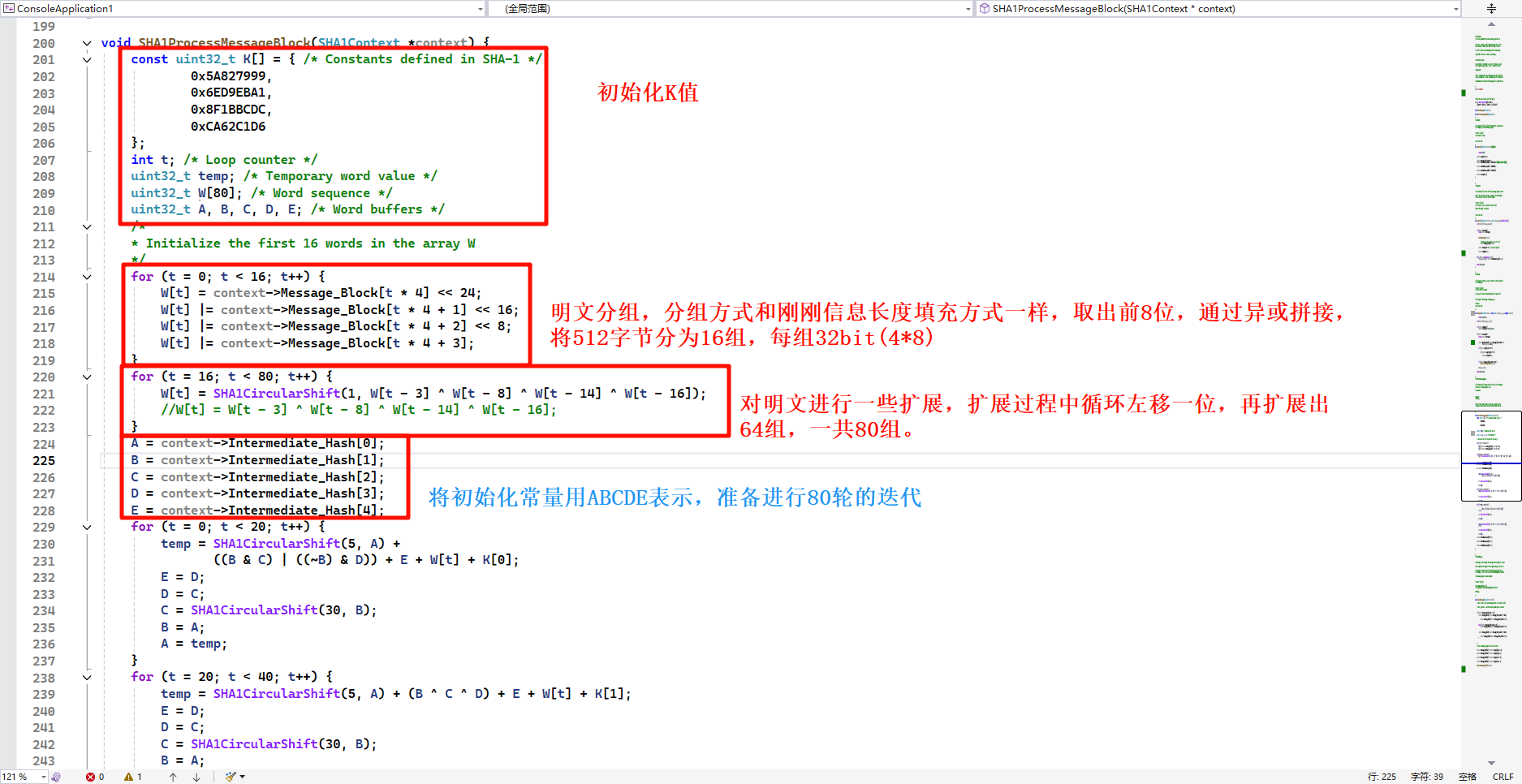
4、SHA1的核心计算过程和MD5差不多,区别是K值只有四个,每二十轮用一个,总共80轮。MD5的K值是有64个的,每轮用一个
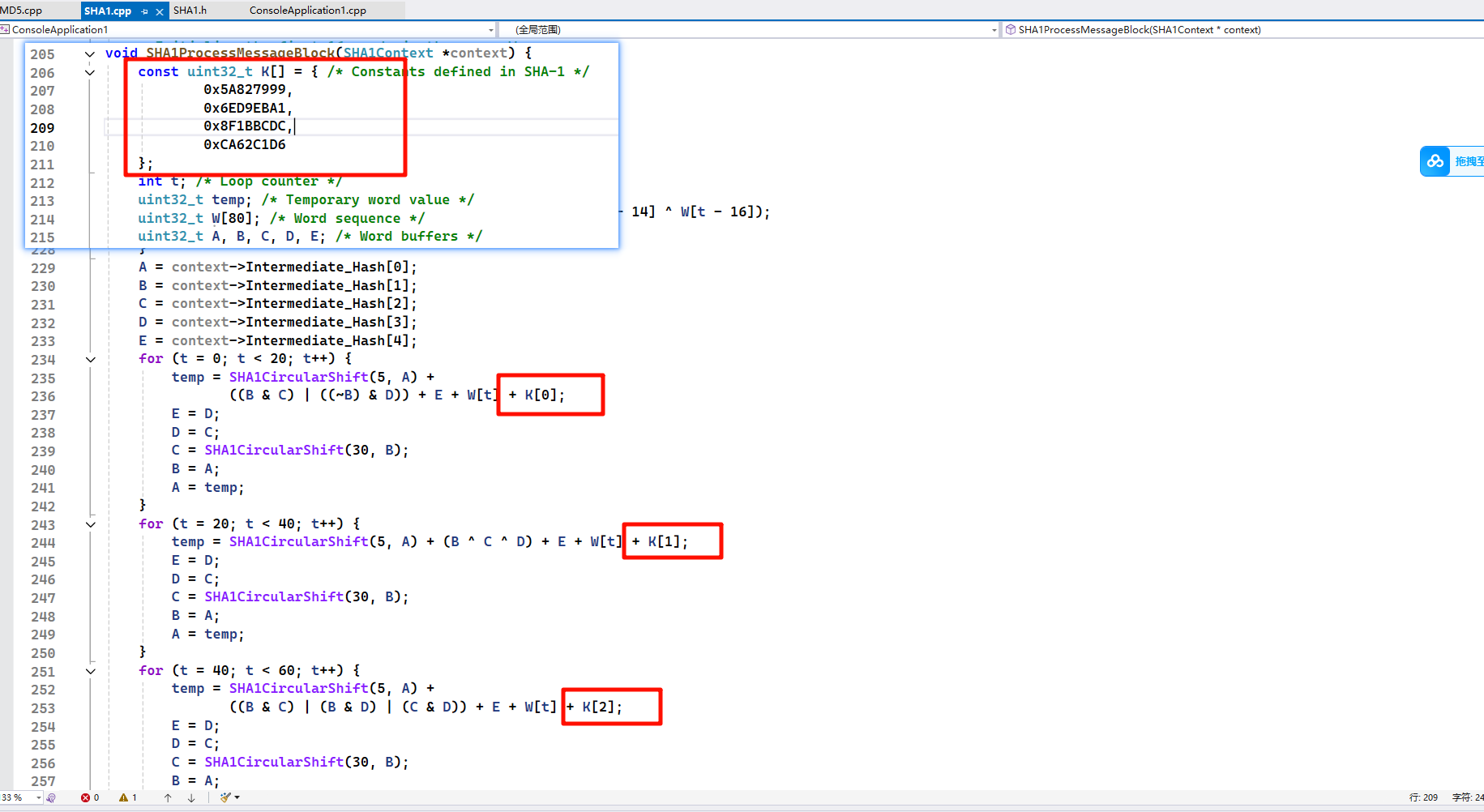
5、SHA1有五个初始化常量,前四个和MD5相同。多出来的一个初始化常量,就是结果比MD5多出来64bit的原因。因为这两个算法都是对初始化常量进行一系列的运算之后,得到摘要结果,初始化常量多64bit,结果自然多64bit。
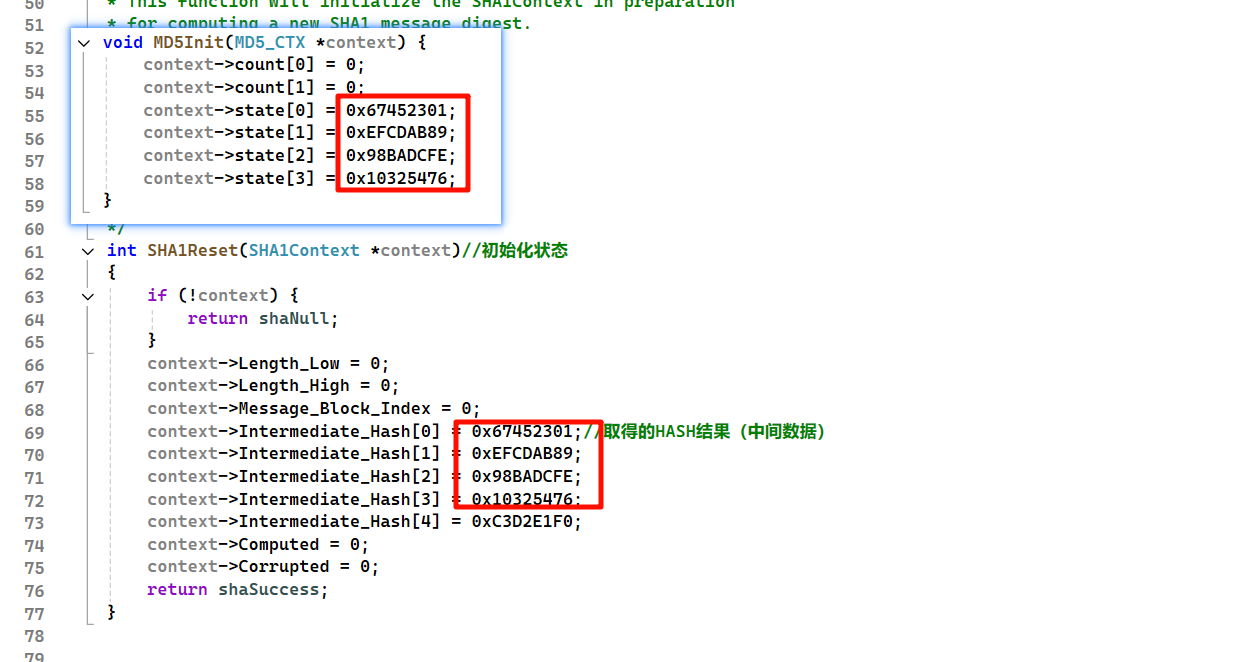
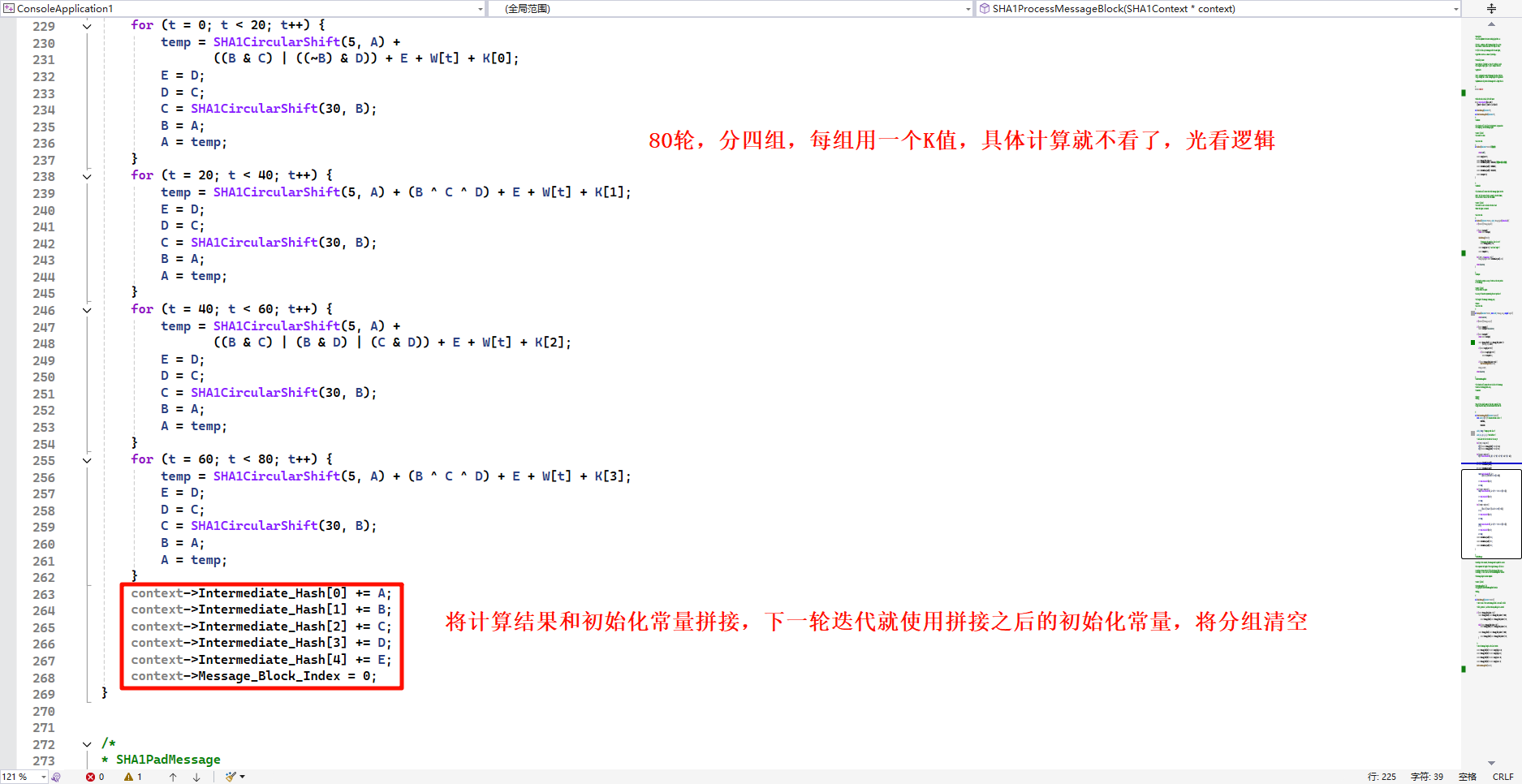
因为SHA1是大端字节序,所以计算之后是将初始化常量直接拼接,MD5是小端字节序,将计算之后的初始化常量倒序拼接
SHA1的明文长度必须小于 2^64
源码分析
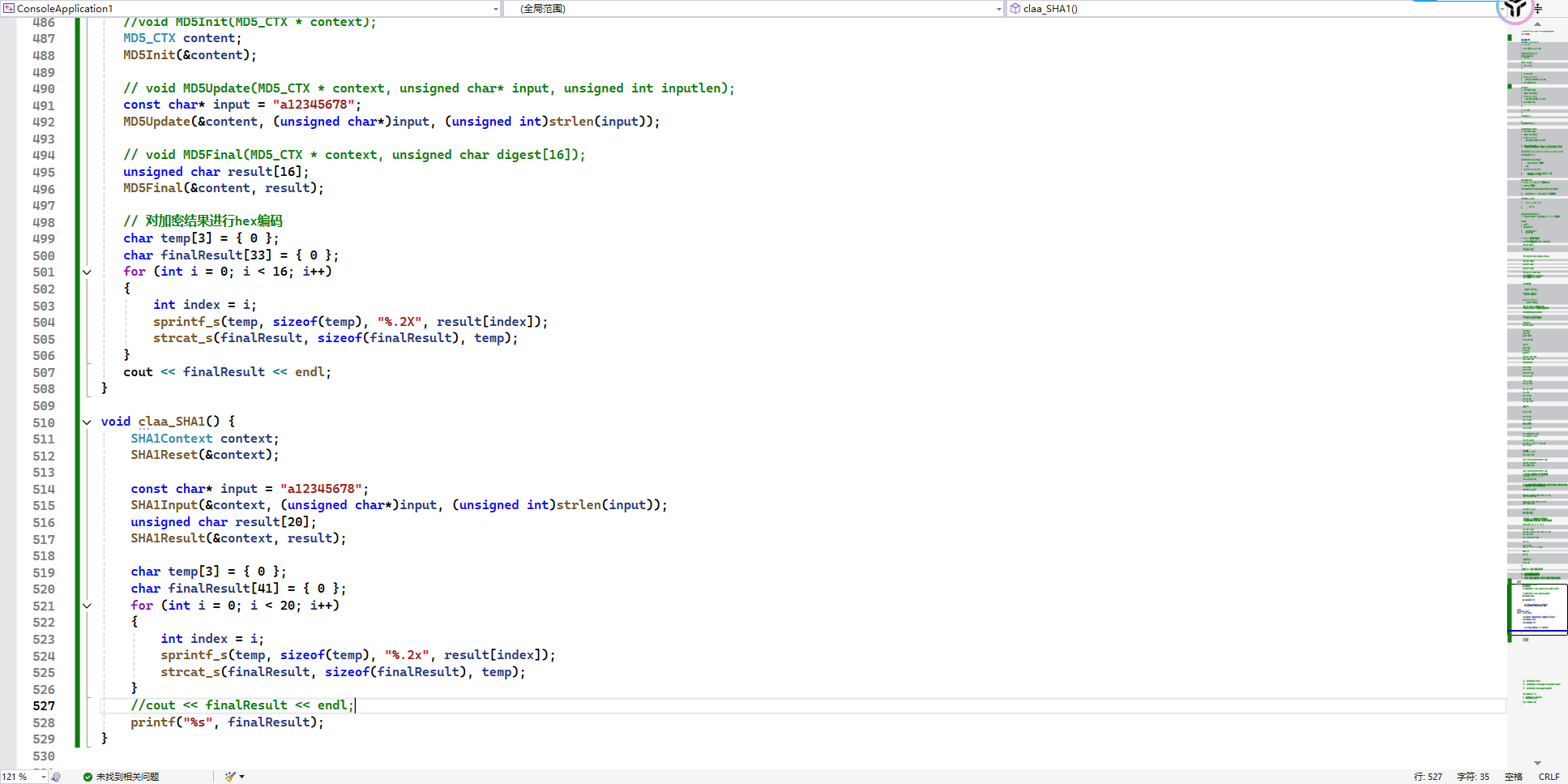
从使用上来说,MD5和SHA1的使用方法大差不差。
MD5init 和 SHA1Reset 初始化
MD5Update 和 SHA1Input 压入数据
MD5Final 和 SHA1Result 计算结果
写法都是一样的,只有传入的位数不一样,给到的result是结果位数,MD5是128bit,SHA1是160位
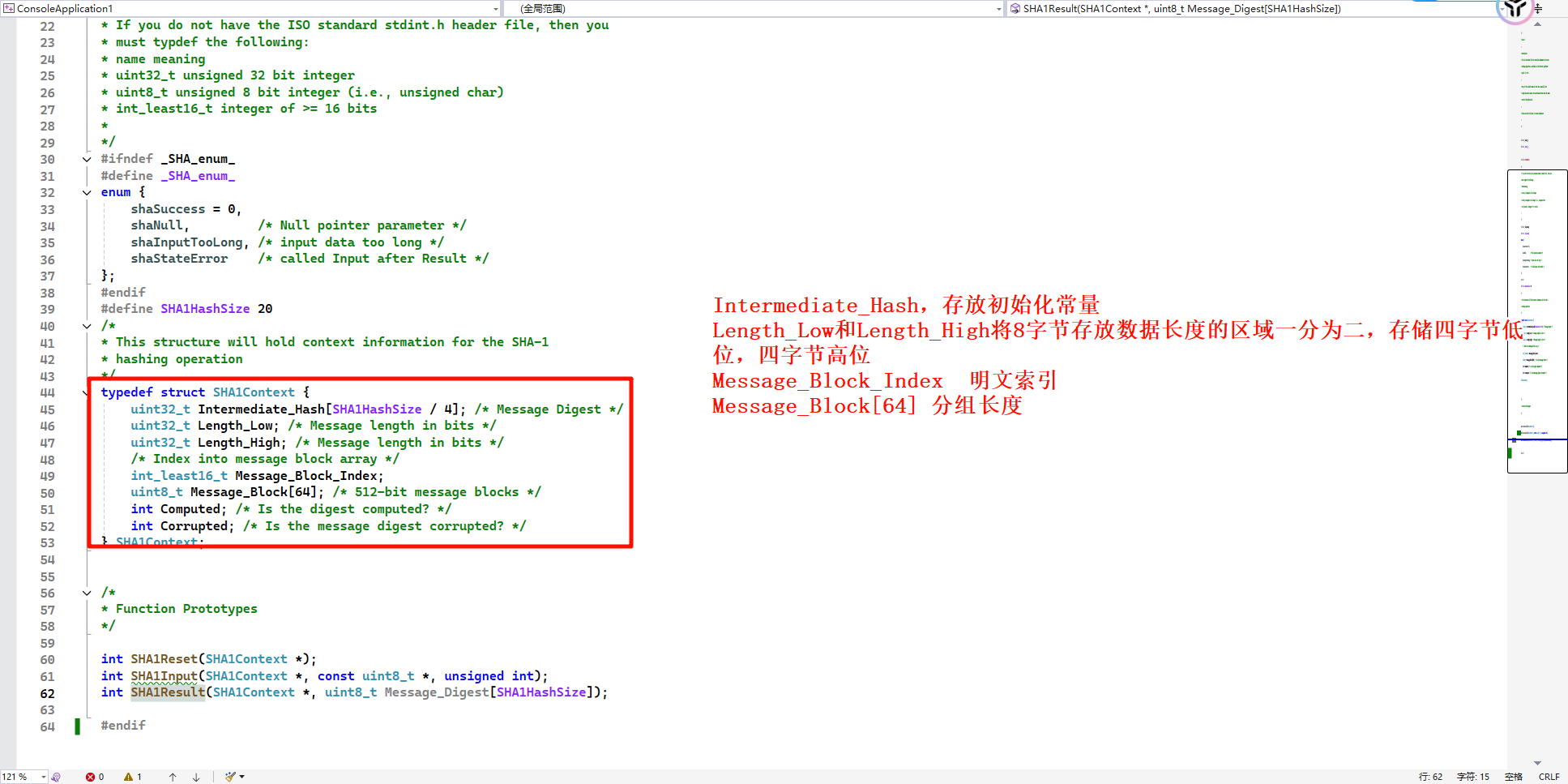
SHA1Reset函数
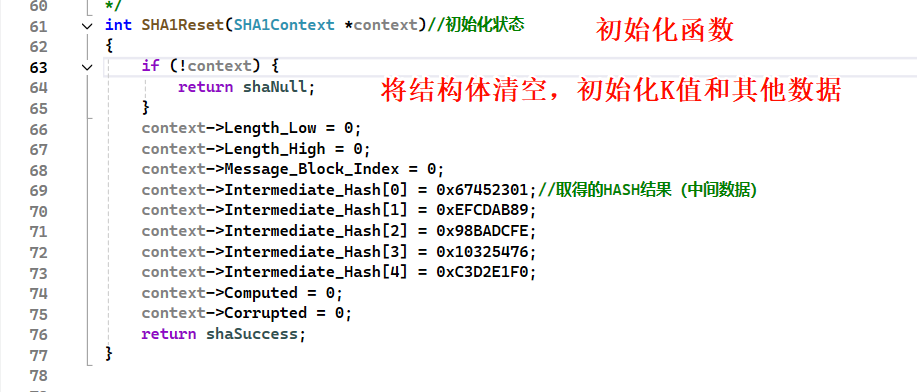
SHA1Input方法:将明文数据压入数组,如果数组满64字节进入 SHA1ProcessMessageBlick 方法计算。和MD5Update同理
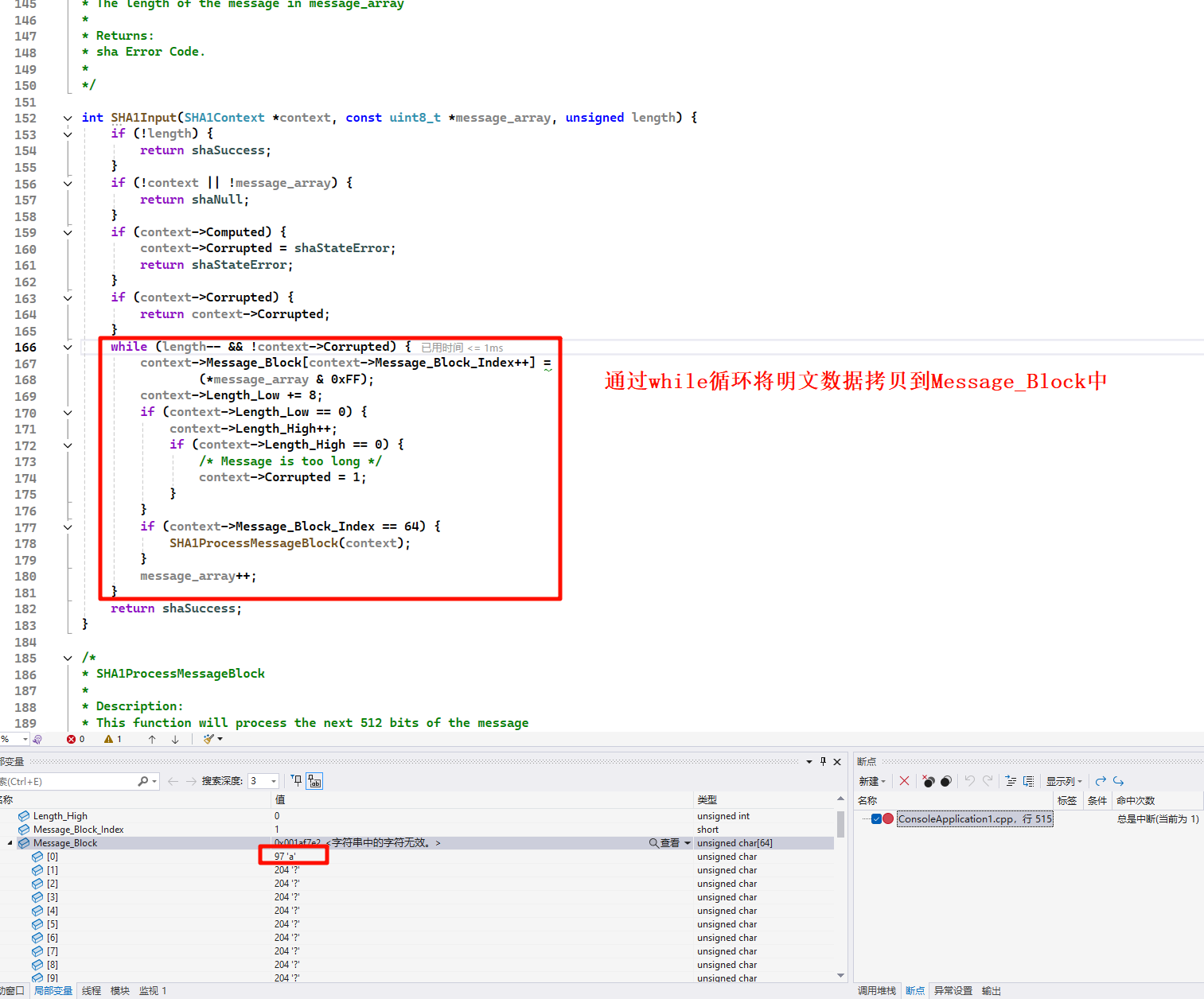
SHA1Result方法。利用传入值做返回值,Message_Digest运算后就是最终结果,将五个初始化常量拼接起来就是Message_Digest。进入SHA1Result时不满512bit,进入 SHA1PadMessage 进行填充
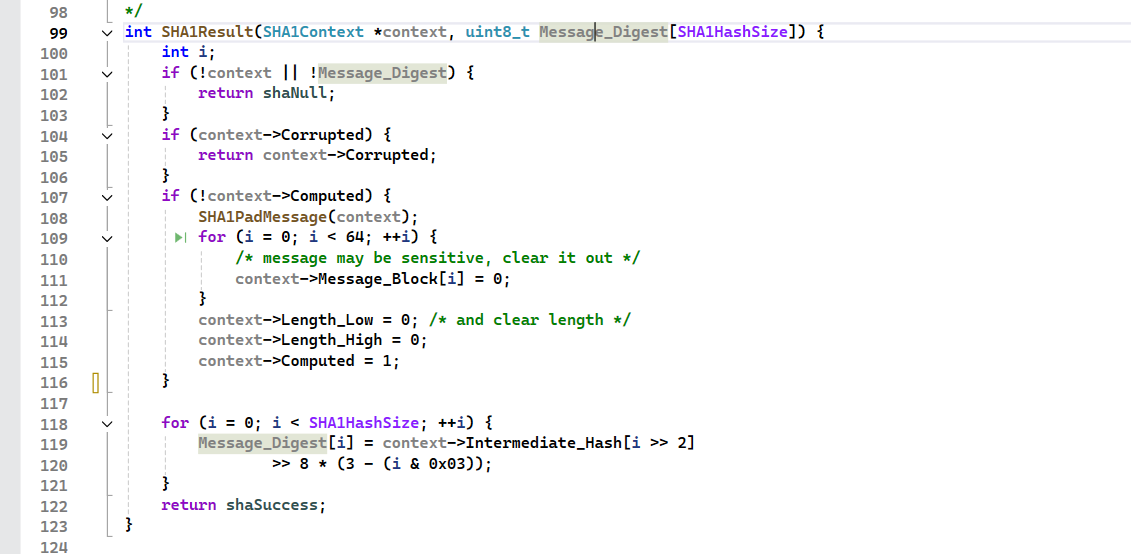
SHA1PadMessage
嘴瓢了,是右移
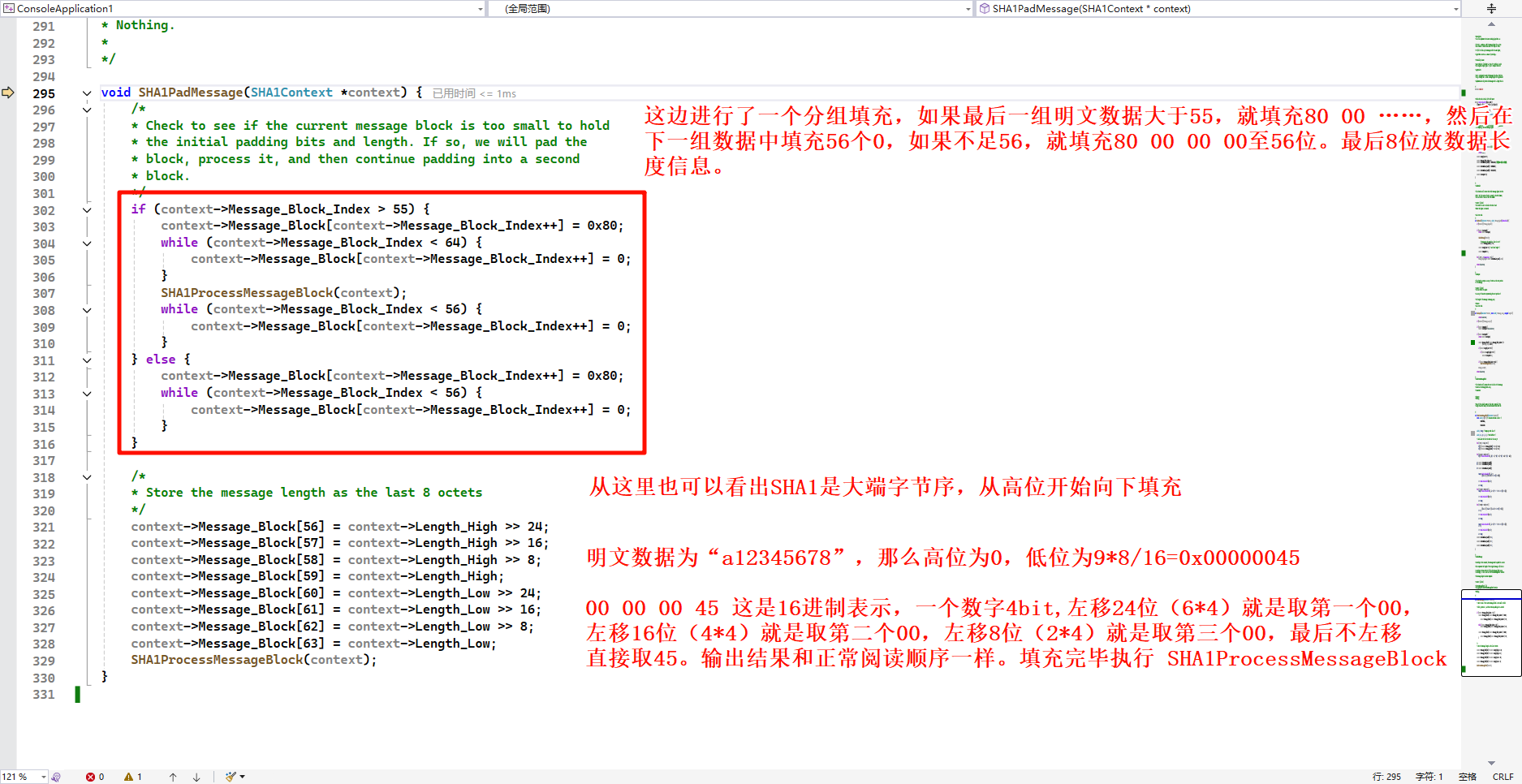
SHA1ProcessMessageBlock 计算方法,对填充成512的分组进行计算
哈希算法特征识别
MD5
1 | a)四个初始化常量 |
SHA1
1 | a)五个初始化常量(前四个和MD5相同) |
SHA256
1 | a)八个初始化常量 |
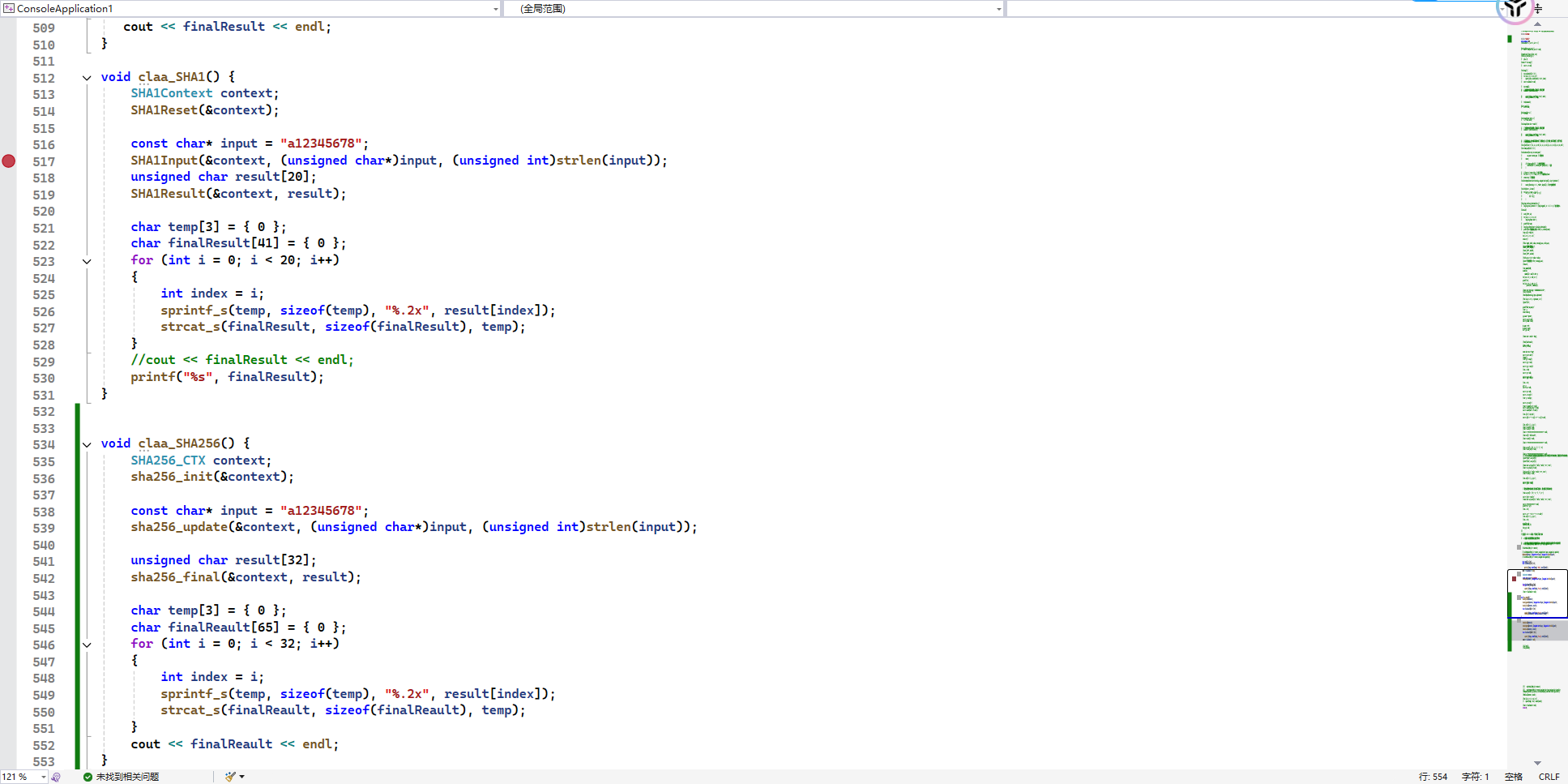
SHA256的一些方法和SHA1简直就像一个模子的东西
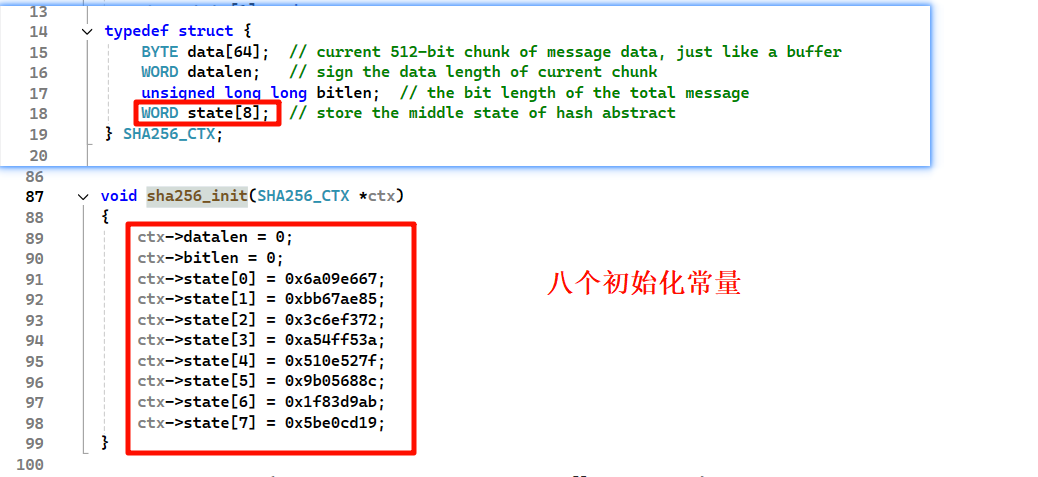
update同样是压入数据的方法,如果足够512字节,进入加密方法,不足512压入数组,等待下一步处理。SHA256的分组同样是512bit
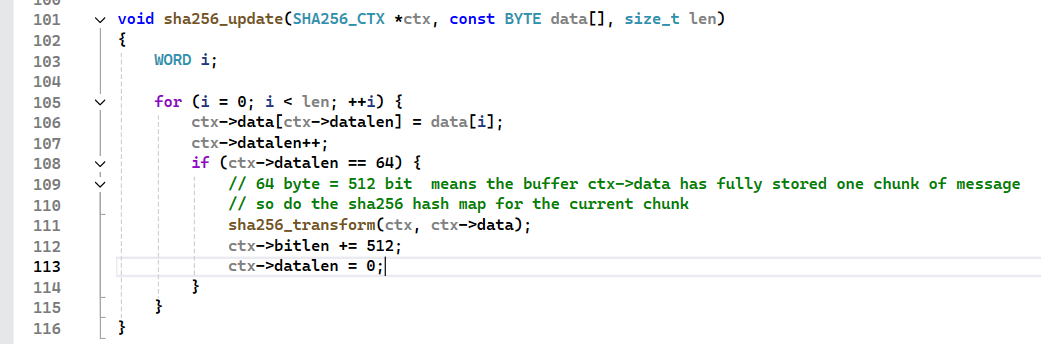
final同理
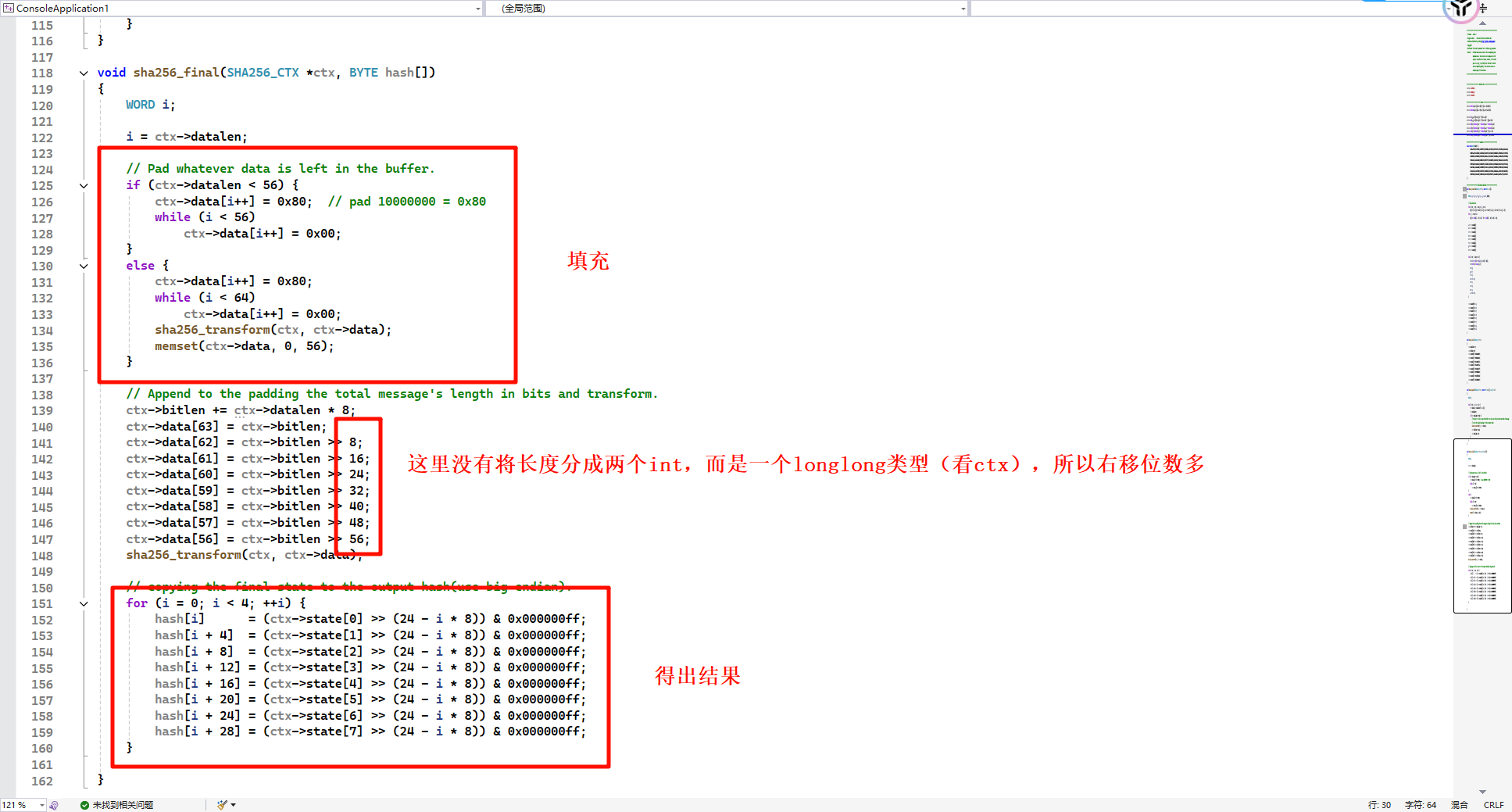
加密方法,需要注意的是和SHA1不同,SHA256是扩充到64组,而非扩充64组(共80组),因为64个K值,循环64次,自然总共64组。
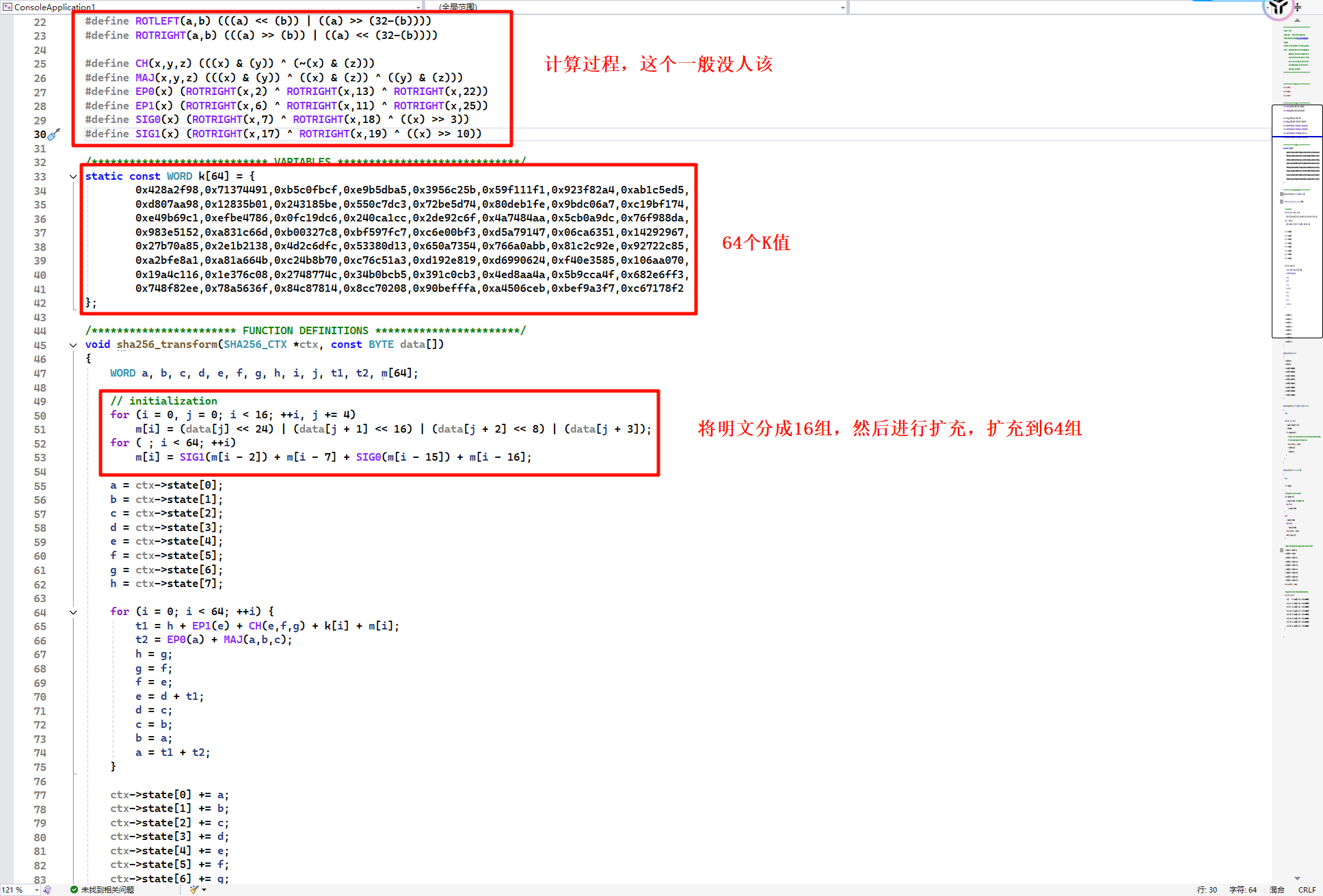
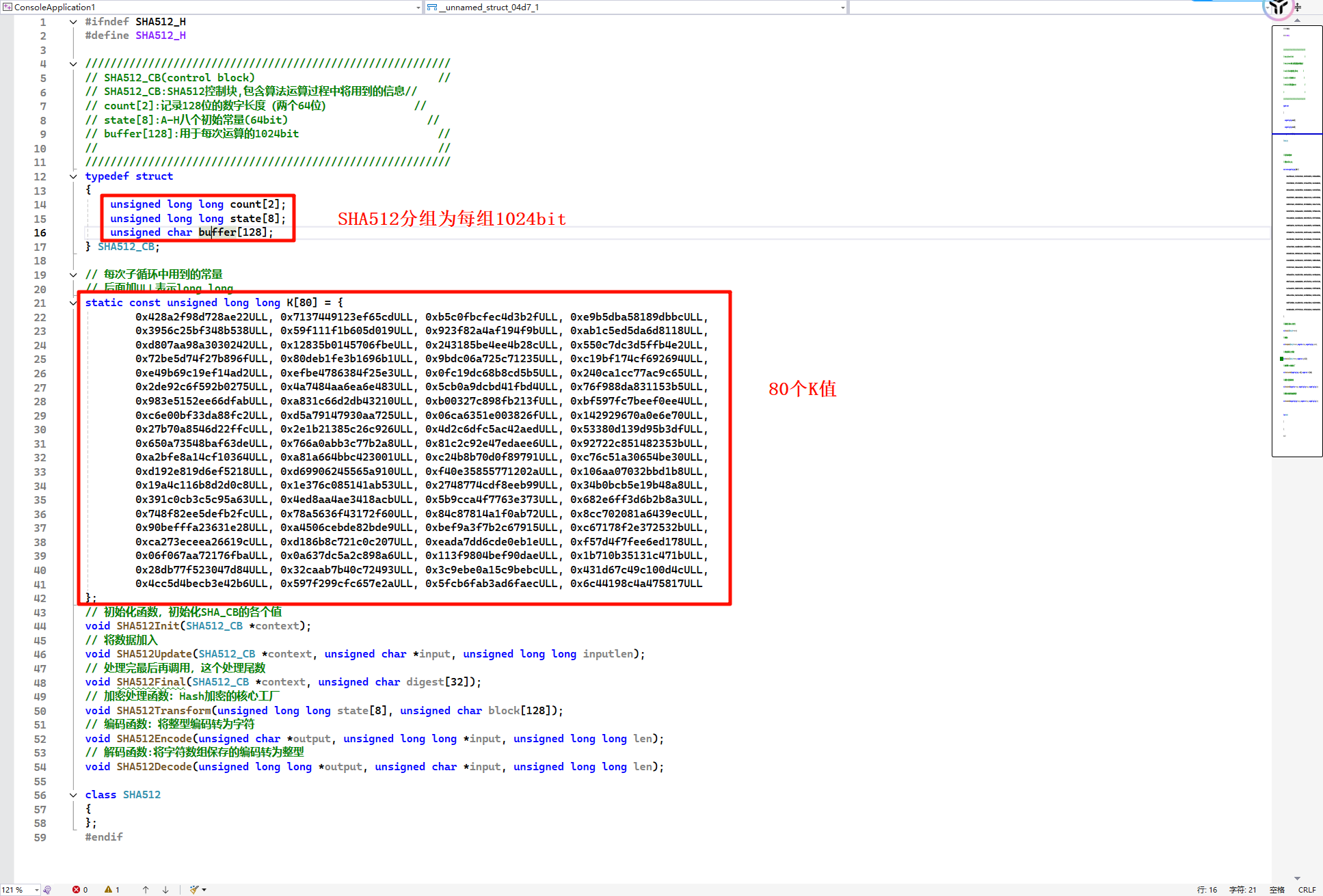
SHA512
1 | a)初始化常量8个,IDA反编译时有时显示为16个,因为初始化常量比其他的长一半 |
SHA512的明文分组是1024bit
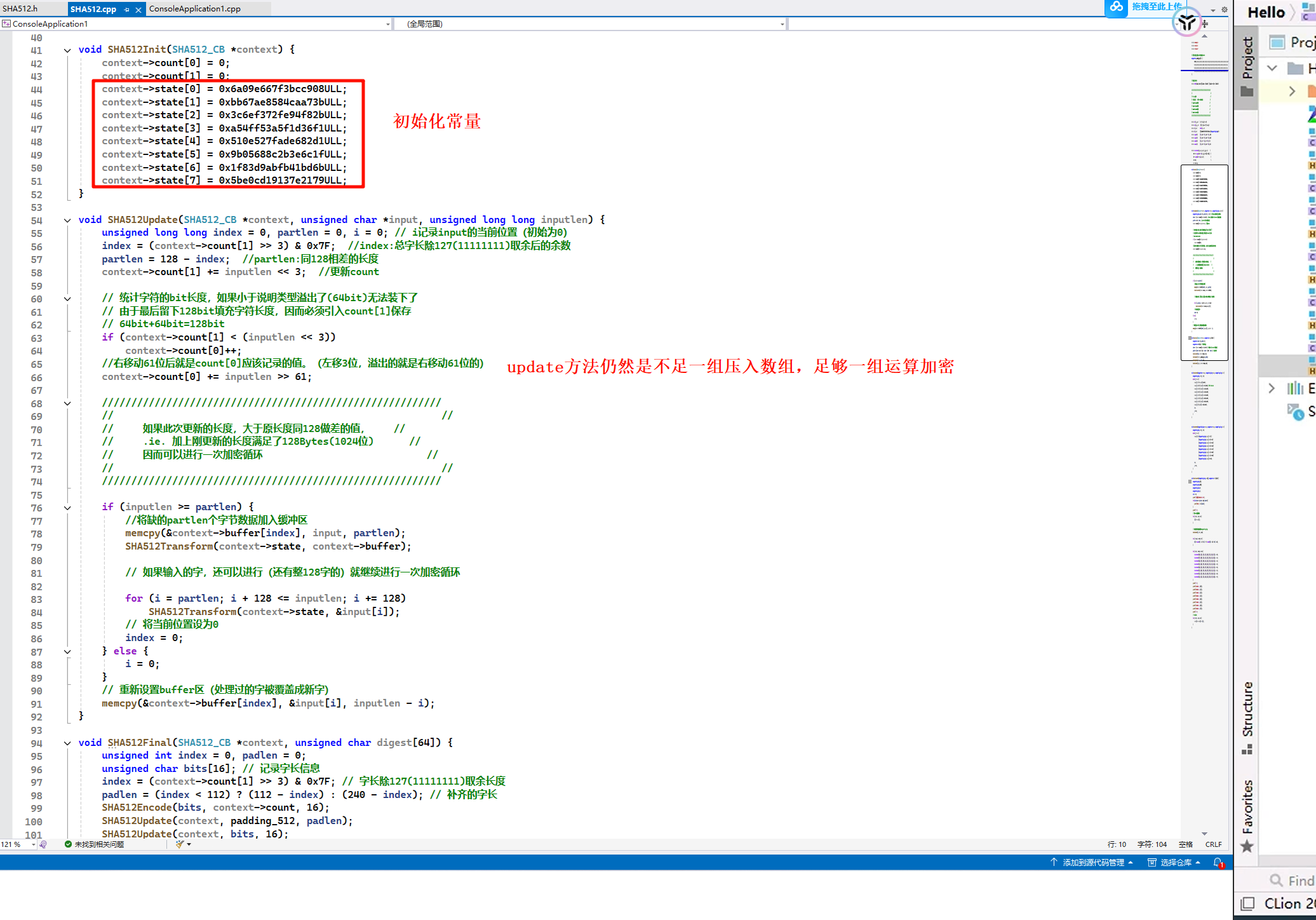
final方法
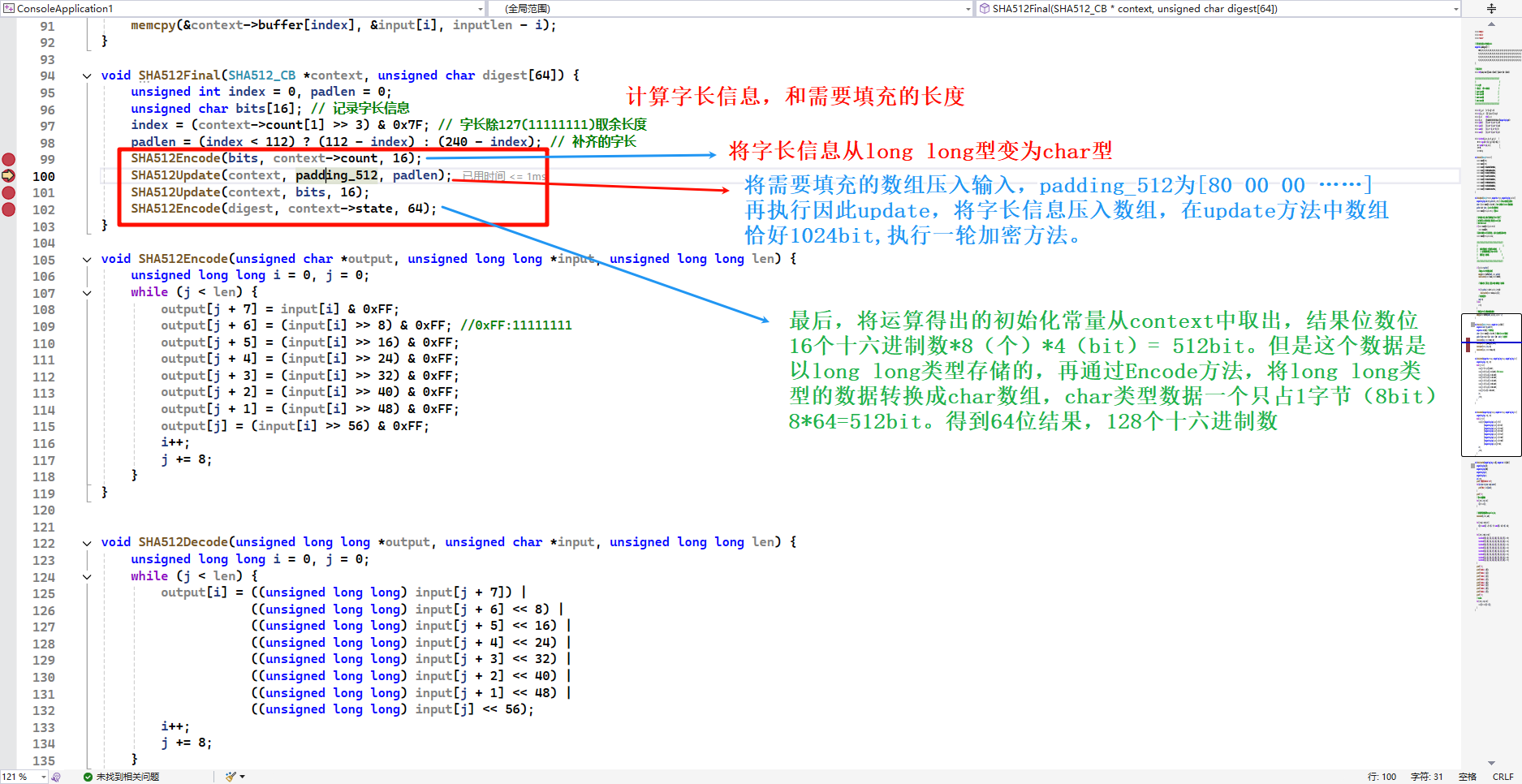
SHA512Decode方法
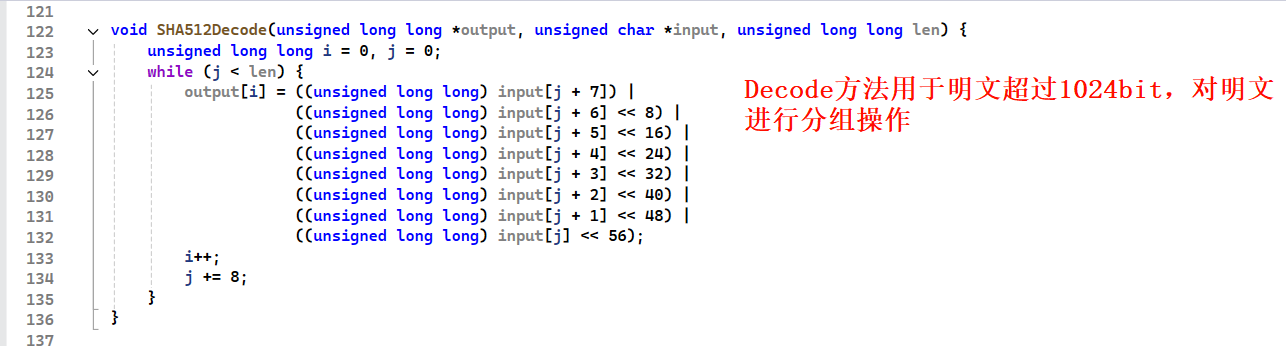
SHA512Transform
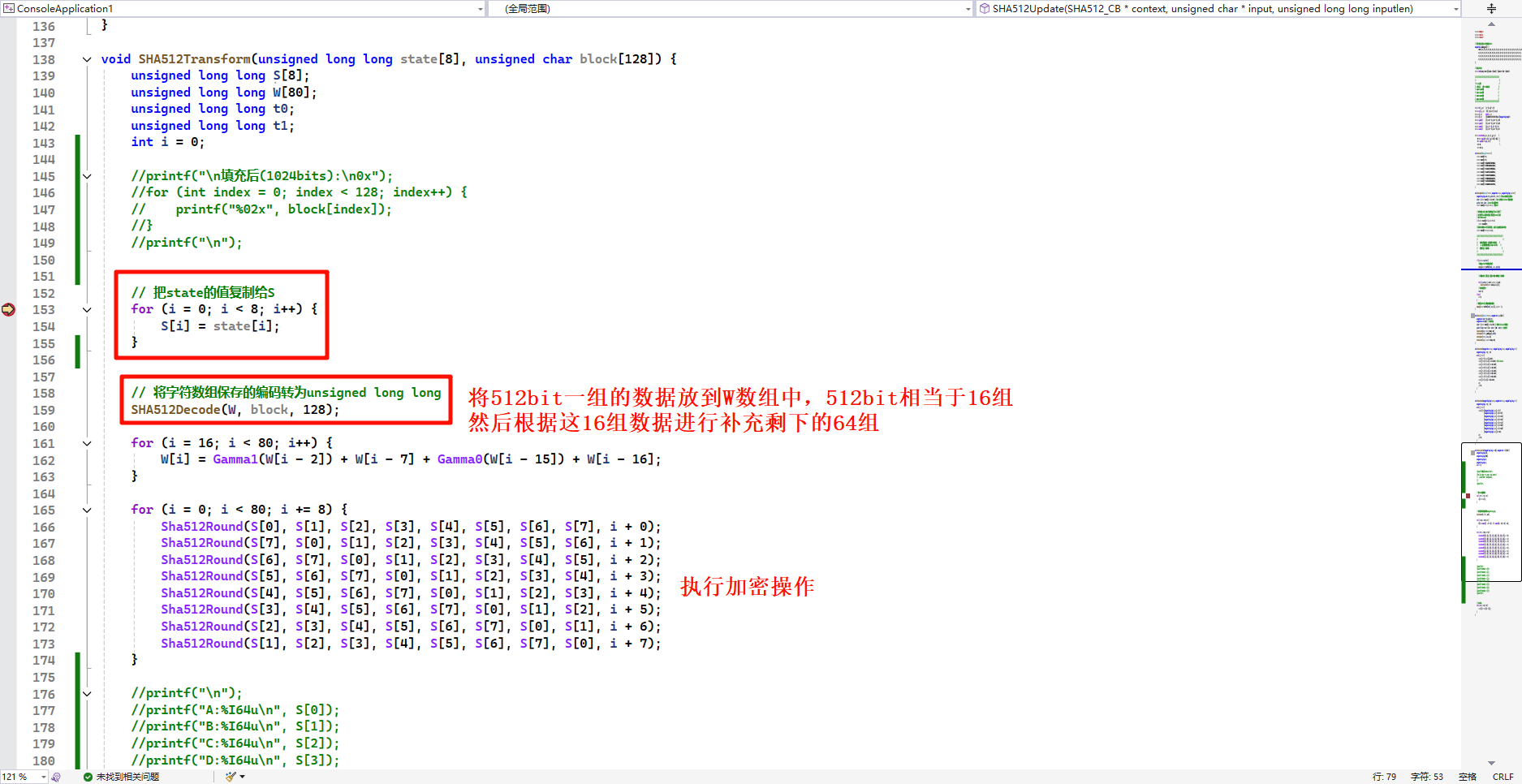
MAC
所谓MAC算法,其实就是两次加盐,两次hash的一种hash算法

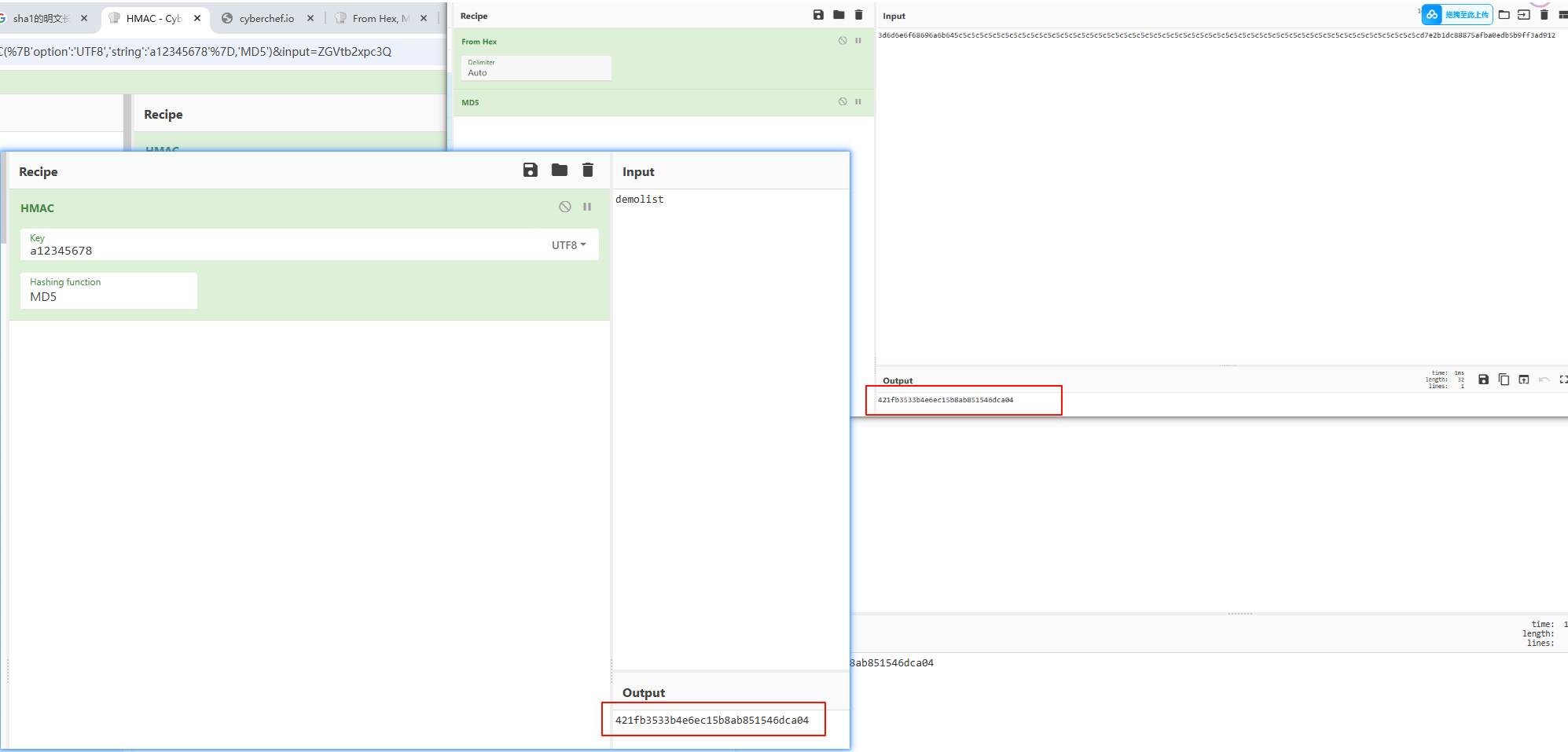
以HmacMD5为例
1 | 1.密钥扩展 |
例:key为 a12345678
明文:demolist
key的hex形式:61 31 32 33 34 35 36 37 38
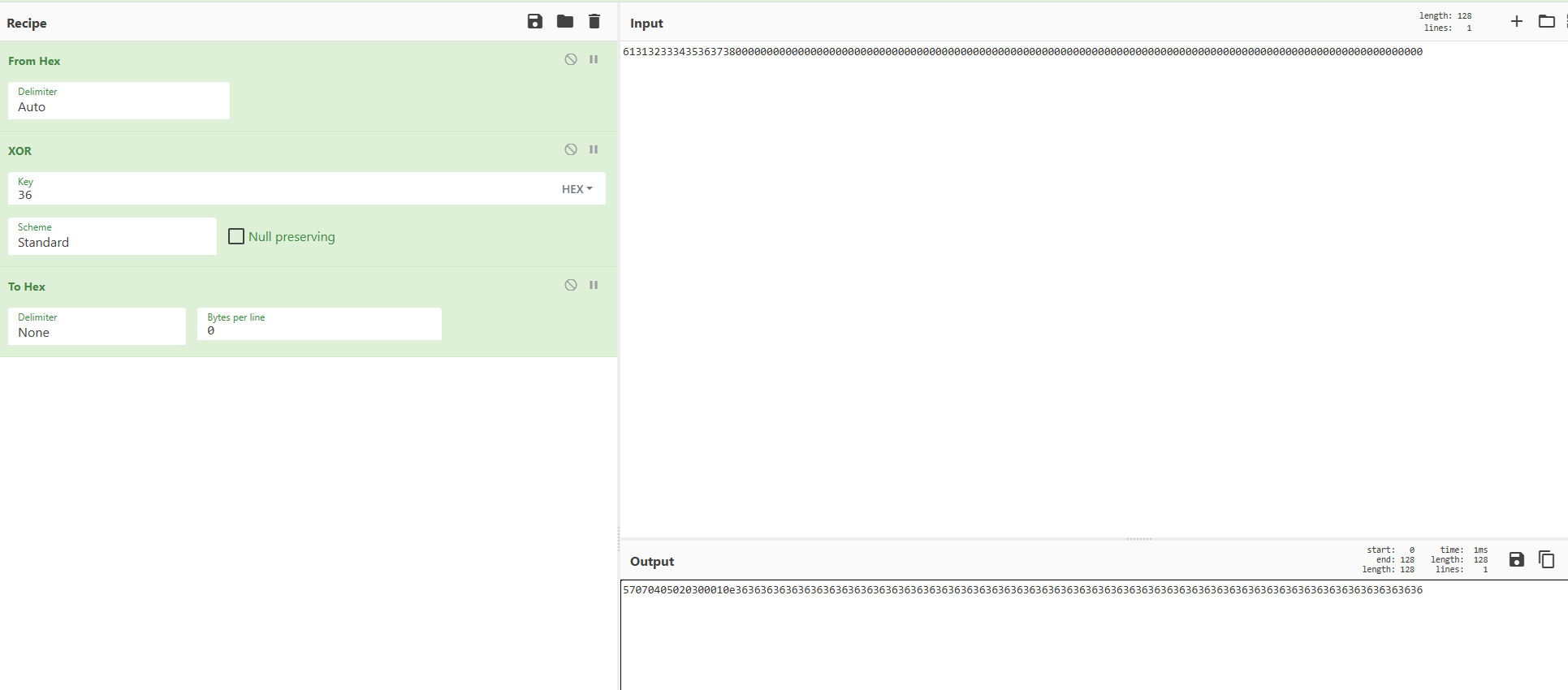
扩展到分组长度的key :61313233343536373800000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
ipad之后的数据:57070405020300010e36363636363636363636363636363636363636363636363636363636363636363636363636363636363636363636363636363636363636
这里使用的网站直接0x36即可,在代码中需要用 3636……3636 (与分组长度相同),来表示。
明文的hex形式:64656d6f6c697374
明文的hex和ipad之后的数据级联:57070405020300010e3636363636363636363636363636363636363636363636363636363636363636363636363636363636363636363636363636363636363664656d6f6c697374
级联后的hash:d7e2b1dc88875afba0edb5b9ff3ad912
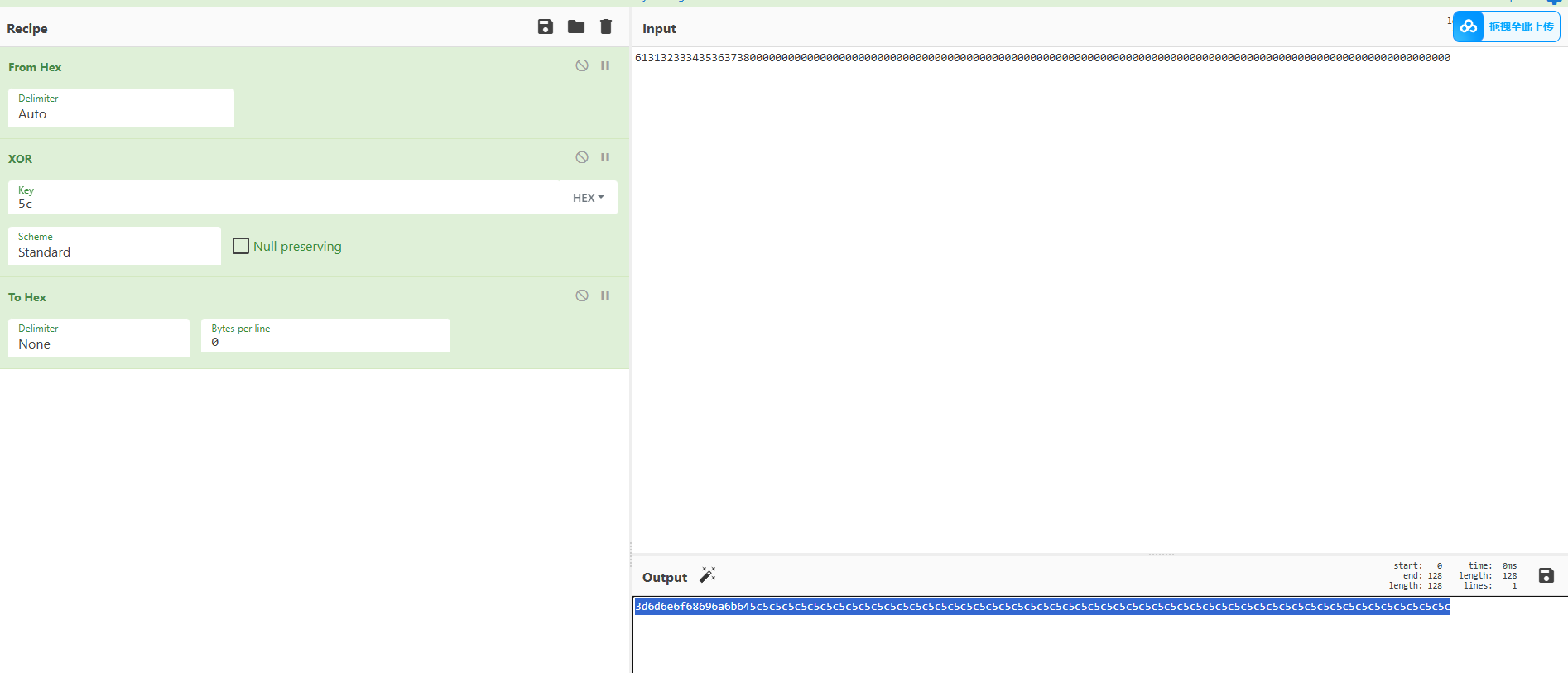
opad之后的数据:3d6d6e6f68696a6b645c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c
opad和hash结果进行级联(拼接)
3d6d6e6f68696a6b645c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5c5cd7e2b1dc88875afba0edb5b9ff3ad912
再次hash就是最后结果:421fb3533b4e6ec15b8ab851546dca04
代码
从代码实现上来看,实现了MD5之后,再实现Hmac_MD5就简单了很多
在代码层面是直接从字节入手的,因此上文各种转换在代码中是不需要的
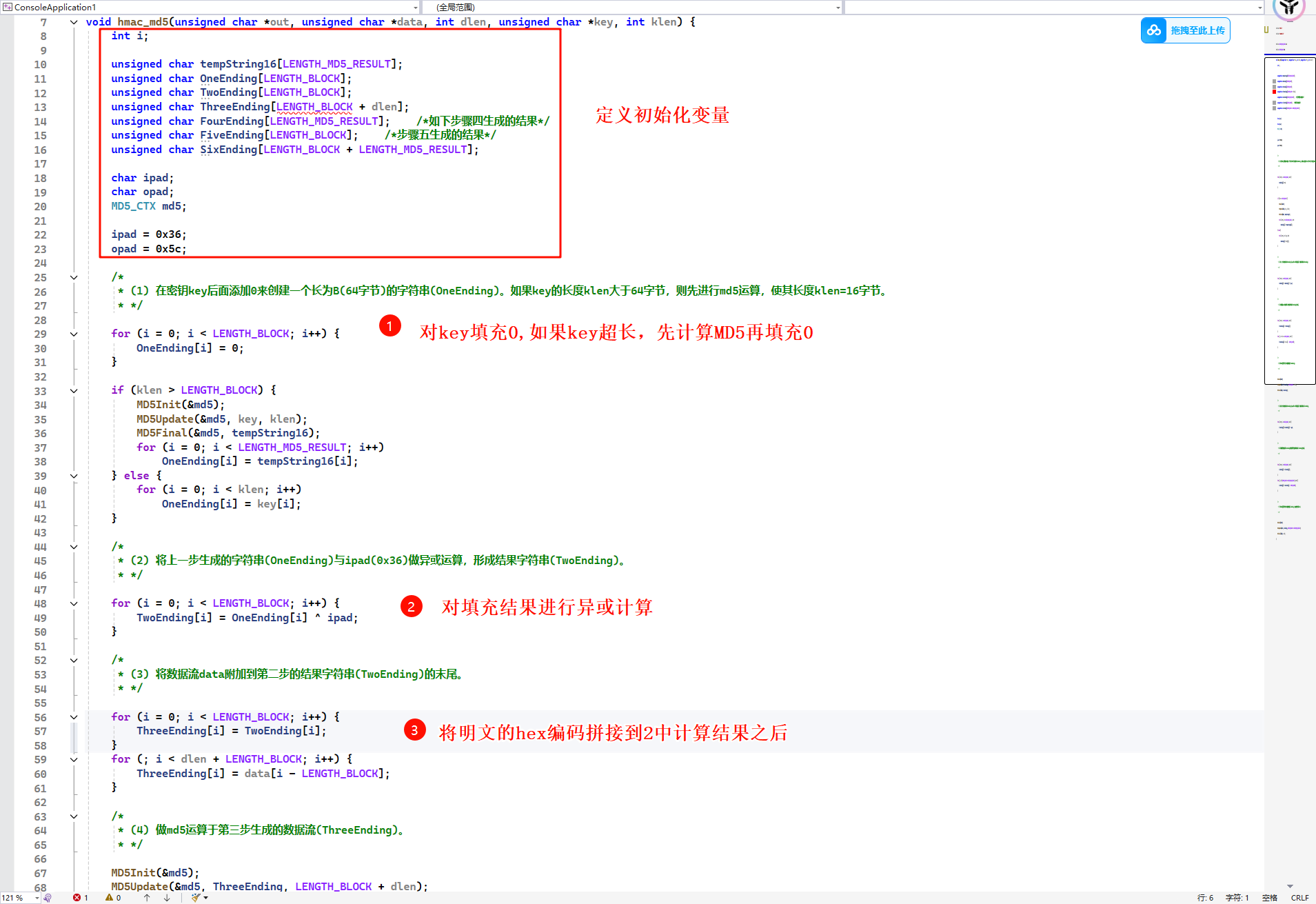

从代码上来看,是很难识别Hmac_MD5算法的,最多识别出来MD5算法,HMAC算法最明显的两个标志是 0x36 和 0x5c 这两个用来异或的。对应十进制数字是 54 92
DES
大佬链接:https://www.anquanke.com/post/id/177808#h3-5
之前已经介绍过DES不安全是因为密钥不唯一,64位的密钥只有56位参与运算,一个字符二进制的最后一位不参与运算。
不考虑填充方式,不考虑加密模式,不考虑IV值,输入明文8字节,输入密文8字节,输出结果8字节
密钥处理流程
1 | 假设有密钥:abcd1234 |
明文处理
1 | 假设有明文:abcd1234 |
逆运算问题,FP表是IP表的逆运算
2
3
4
5
6
7
8
9
62, 54,46, 38, 30,22, 14, 6, 64,56,48, 40, 32, 24, 16, 8,
57,49,41, 33, 25,17, 9, 1, 59,51,43, 35, 27, 19, 11, 3,
61, 53, 45, 37, 29, 21, 13, 5, 63, 55, 47, 39, 31, 23, 15, 7]
FP_Table = [40, 8, 48, 16, 56, 24, 64, 32, 39, 7, 47, 15, 55, 23, 63, 31,
38, 6, 46, 14, 54, 22, 62, 30, 37, 5, 45, 13, 53, 21, 61, 29,
36, 4, 44, 12, 52, 20, 60, 28, 35, 3, 43, 11, 51, 19, 59, 27,
34, 2, 42, 10, 50, 18, 58, 26, 33, 1, 41, 9, 49, 17, 57, 25]为什么说是逆运算呢,就是将打乱的顺序再弄回去,比如,IP表第一个是58,明文进来二进制的第一个就去了第58位,FP表中的1在表中的第五十八个,就相当于,将在第58位的第一个二进制数又放了回去。以此类推
代码详解
留出来了四个方法,先看生成加密子密钥的方法

生成子密钥

SubKey是全局变量
加密过程
关于代码中没有体现L16和R16互换的这个问题:
这里的最后是不需要L16和R16颠 倒,因为每次运算都暗含了左右颠倒,这个运算并不是L一直在左边,而是让在左边的数叫Li,其实数据一直在左右变换,左边的数据变换到右边之后还要进行一个异或操作,从L1开始到L16,正好运算后完毕之后左边的数据在右边,右边的数据在左边,就不需要进行交换操作,而进行语言描述的的时候添加了这个状态,因此会说L16R16互换
循环加密完毕之后进行末置换转换成十六进制之后得到密文

解密和加密大差不差,DES的魔改点还是很多的,因为里面有很多表,比如明文的初始置换和末置换,这个修改不会影响安全性。还有S盒修改和白盒,白盒就是将密钥融入到算法里,一般是AES起步,但是结果还是标准的结果,只是拿不到密钥
分组加密的填充
DES数据分组密码,明文8个字节一组进行加密,当明文长度不足一个分组时就需要填充,以PCKS7为例
1、如果明文没有内容或者明文刚好是分组长度的整数倍,都需要填充一个分组,因此填充内容在8-64bit。
2、如果填充一个分组,那么填充内容是 08 08 08 08 08 08 08 08,明文七个字节填充 01,六个字节填充 02 02。
3、如果明文里有半个字节,先补0再填充,如果只有半个字节a,填充结果为
0a 07 07 07 07 07 07 07
加密模式
当明文长度超过一个分组时,就需要考虑加密模式了,不可能废那么大劲只加密8字符。加密模式包括 CBC CFB OFB CTR ECB。常用的有 CBC、ECB、CFB、OFB
ECB模式比较简单,就是每个分组单独加密,分组直接没有关联,可以分段解密,也可以通过替换某段密文,来达到替换明文的目的。这个不安全,之前也提到过。
CBC模式,引入了一个值,IV值,多了一个处理,就是这一轮的明文先和上一轮的进行异或,得到的结果再去运算,第一轮明文和IV值进行异或。这样确实安全了不是,但是是单线程,计算依赖上一轮结果,计算速度慢
CFB
CFB模式是一种流密码加密,不属于分组加密
CFB模式是先将IV值使用key作为密钥进行ECB模式的DES加密,得到的结果再作为IV值执行CBC模式
OFB
一个分组的OFB模式和CFB的流程是一样的,两个分组的OFB模式,第二个分组是明文和加密两次的IV值异或的结果
3DES
密钥24字节,等于3个DES的密钥,顾名思义嘛,执行三次DES,将密钥分成三段,第一个用于加密,第二个用于解密,第三个加密解密后的结果。
当前两段密钥相同时,3DES的结果就是一次单独的第三个密钥DES加密。
DES有安全问题时到AES出现之前的产物,增加DES密钥被穷举爆破的难度
AES
算法特点
AES算法还有个小名 Rijndael,Rijndael 算法本身分组长度是可变的,但是被确定为AES之后,分组长度只有128bit一种了
密钥长度为 128bit、192bit、256bit,分组长度为128bit。
AES128是10轮运算,AES192是12轮运算,AES256是14轮运算。DES 16轮
明文处理
先以最简单的ECB模式为例,假设明文为 abcd1234efgh1234 密钥为1234567887654321
明文state化
将明文转换成十六进制的形式,然后按照下表排列 61626364313233346566676831323334
| 61 | 31 | 65 | 31 |
|---|---|---|---|
| 62 | 32 | 66 | 32 |
| 63 | 33 | 67 | 33 |
| 64 | 34 | 68 | 34 |
数据竖向排列,明文密钥进行同样的处理
| 31 | 35 | 38 | 34 |
|---|---|---|---|
| 32 | 36 | 37 | 33 |
| 33 | 37 | 36 | 32 |
| 34 | 38 | 35 | 31 |
首先将state化之后的明文和种子密钥K进行异或,种子密钥就是用户输入的密钥,下面的子密钥是种子密钥拓展出来的,进行多少轮加密,扩展多少子密钥。
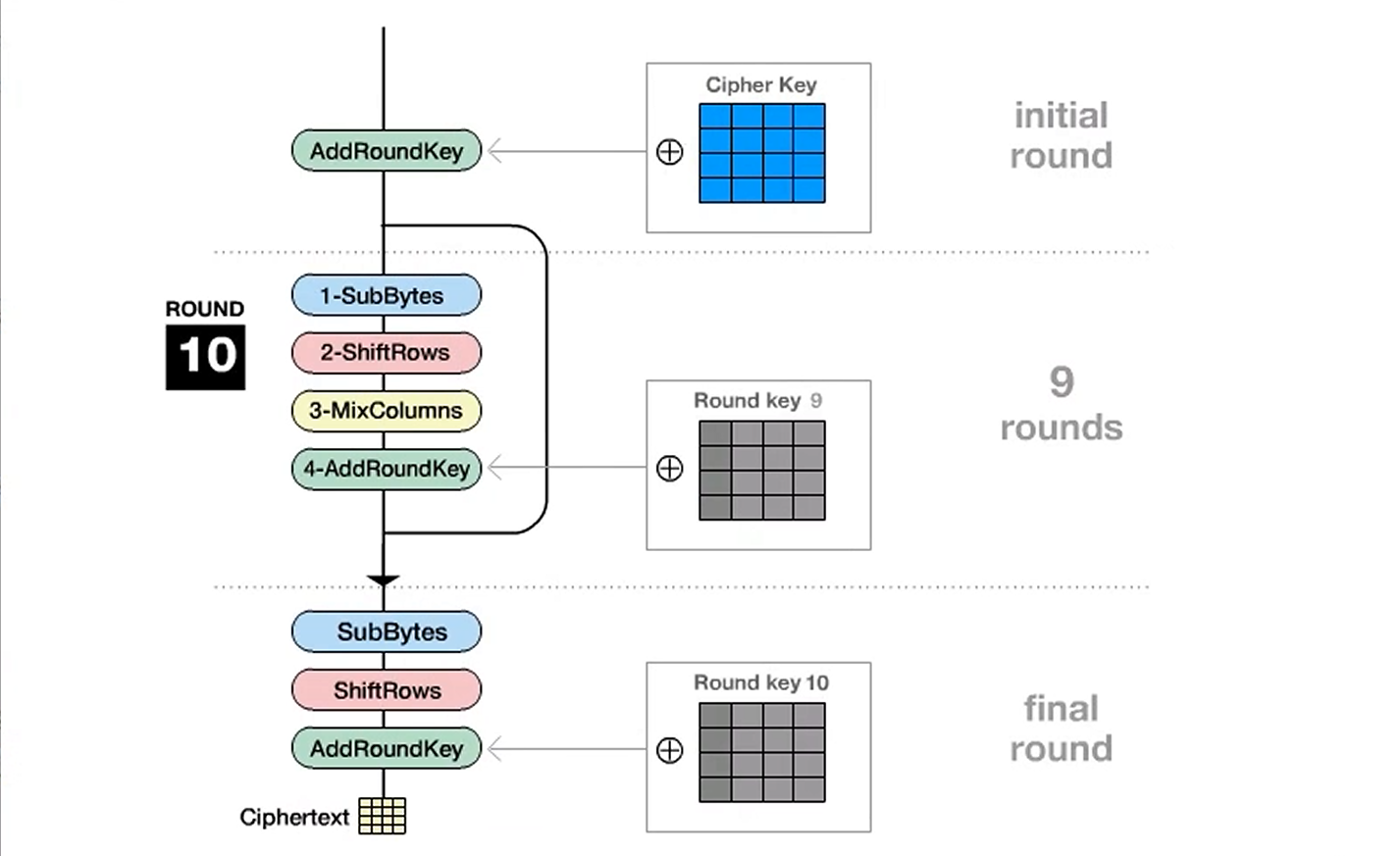
进行九轮运算,进行sbox替换,循环左移,列混合,state与子密钥K1-K9异或
前面提到过128bit的密钥进行10轮,还要一轮末运算,进行sbox替换,循环左移,state与子密钥K10异或。但是不进行列混合运算了。完毕之后得到密文
SubBytes(s-box替换)

根据state表中的十六进制数指示的去替换成表中的数据,值得注意的是DES加密的S盒有8个,AES加密的S盒只有这样一个,但是AES加密和解密用的不是同一个盒。但是两个盒是有着顺逆关系的。
1 | 61 31 65 31 |
ShiftRows(循环左移)
这个操作比较简单,针对state表中的数据进行操作,第一行不动,第二行左移一个,第三行左移两个,第四行左移三个。
1 | 以经过S盒替换的数据为例 |
这样就完事了
MixColumns(列混合变换)
https://blog.csdn.net/u012620515/article/details/49893905
https://bbs.kanxue.com/thread-147205.htm
这一步就相当复杂了
列混合存在一个 4*4 的矩阵
1 | 02 03 01 01 |
将左移之后的数据,这个矩阵的每一行与状态矩阵的每一列进行矩阵乘法运算,得到新的状态矩阵列。
伽罗瓦域运算
在矩阵乘法中,所有的加法和乘法运算都是在伽罗瓦域GF(2^8)中进行的。这个加法实际上就是异或运算,乘法有其他规则
乘01,返回结果是字段本身
乘02,相当于将二进制数据左移一位,如果最高位原本是1,左移之后需要与 0x1B (0001 1011)进行异或运算。如果不是一,直接左移一位
乘03,先进行乘02处理,然后将处理后的结果与原字节进行异或运算。
做运算的时候,将state状态矩阵的每一列,与列混合矩阵的每一行进行运算,得到新的列值。用坐标表示就是 (1,1)与(1,1)运算 ,(2,1)与(1,2)运算,(3,1)与(1,3)运算以此类推。
这个列混合运算的过程就有几个特征点,比如4*4的矩阵和 0x1B,0x80
AddRoundKey(异或)
将列混合变换后的结果和拓展过的Ki进行异或操作。
然后重复上述操作,一共执行九轮,第十轮没有列混合运算,得到密文
密钥编排
先将密钥的十六进制state化,然后以列为单位分为 Wi
Wi = Wi-1 ^ Wi-4,这个是一个拓展公式,当 i 能整除 4 的时候,则是先左移一位,然后去S盒中进行替换操作,再进行异或
示例
1 | 将刚刚state化的密钥拿来 |
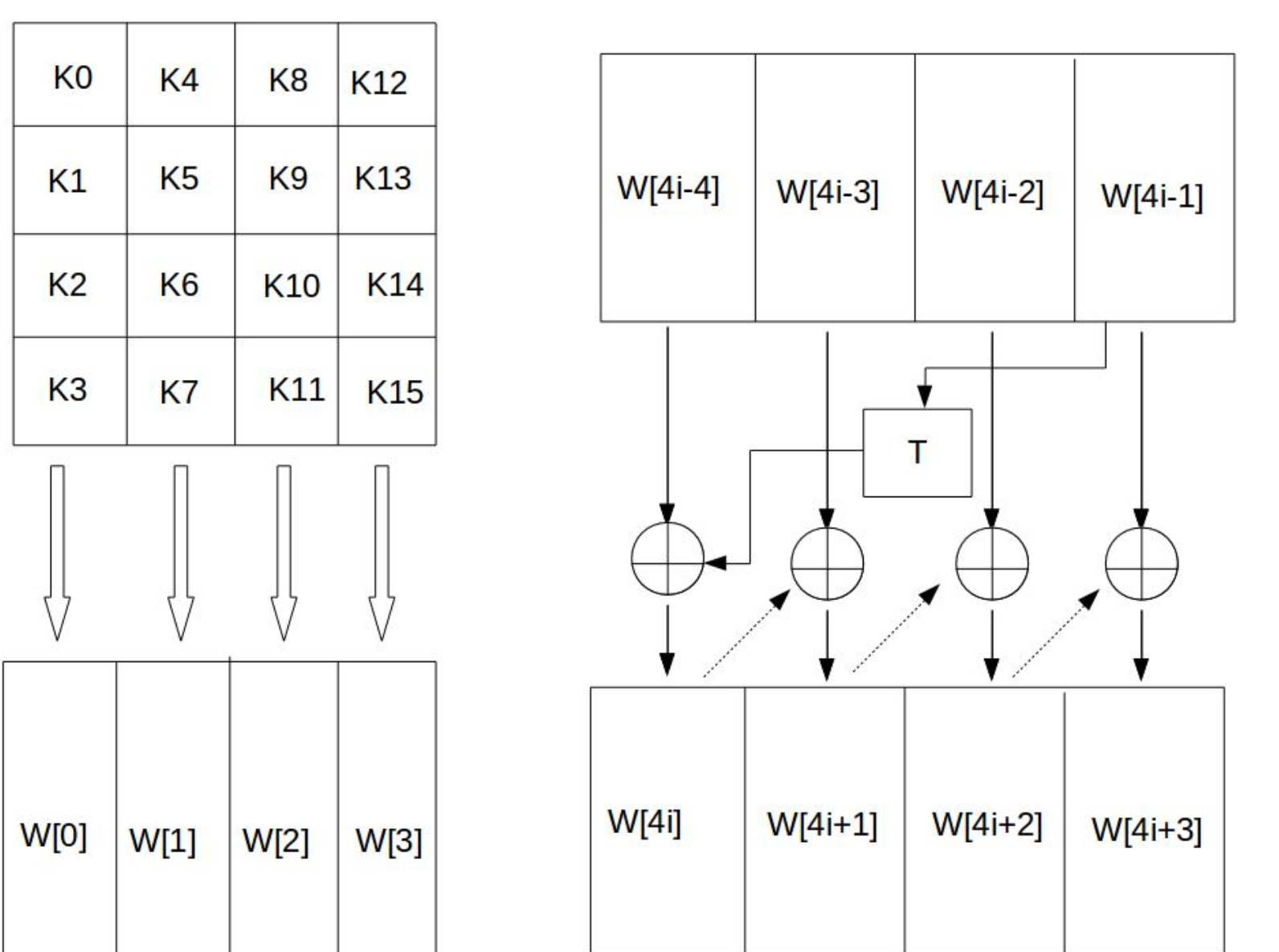
一共生成 4-43 四十个子密钥加上种子密钥一共 44 个,总共使用十一轮,一轮使用四种,种子密钥在开始轮换之前 AddRoundKey 异或的就是种子密钥。这样的子密钥是算出来的,还有一种查表法,直接查,加密速度更快。只是内存较计算的占用多
查表法
查表法进行的操作就是将S盒替换、循环左移和列混合融合成一步。跳过计算过程,直接去取值,运算速度加快
https://zhuanlan.zhihu.com/p/42264499
查表法对内存配置有一定要求,目前是没啥大事了,好多软件中的AES已经使用了查表法,运算速度快